Fundamentos de optimización#
En este notebook demostramos cómo configurar un flujo de trabajo de segmentación de imágenes y optimizar sus parámetros con una anotación dispersa dada.
Ver también:
from skimage.io import imread
from scipy.optimize import minimize
import numpy as np
import pyclesperanto_prototype as cle
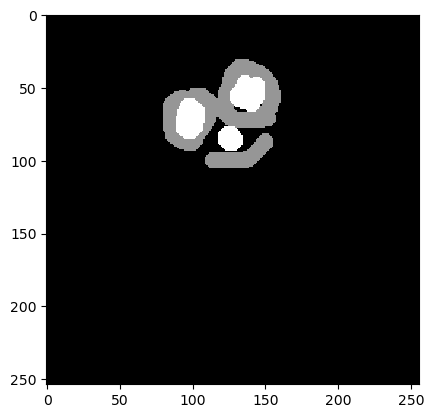
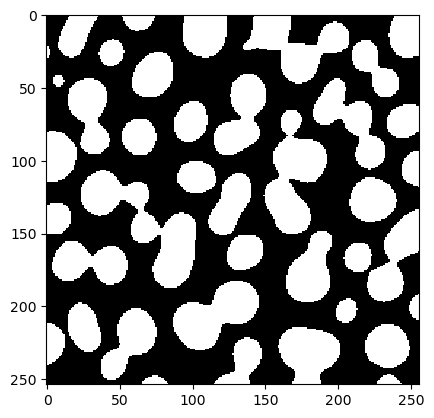
Comenzamos cargando una imagen de ejemplo y una anotación manual. No todos los objetos deben estar anotados (anotación dispersa).
blobs = imread('../../data/blobs.tif')
cle.imshow(blobs)

annotation = imread('../../data/blobs_annotated.tif')
cle.imshow(annotation)
A continuación, definimos un flujo de trabajo de procesamiento de imágenes que resulta en una imagen binaria.
def workflow(image, sigma, threshold):
blurred = cle.gaussian_blur(image, sigma_x=sigma, sigma_y=sigma)
binary = cle.greater_constant(blurred, constant=threshold)
return binary
También probamos este flujo de trabajo con algunos valores aleatorios de sigma y threshold.
test = workflow(blobs, 5, 100)
cle.imshow(test)
Nuestra función de aptitud toma dos parámetros: Un resultado de segmentación dado (test) y una anotación de referencia. Luego determina qué tan buena es la segmentación, por ejemplo, usando el índice de Jaccard.
binary_and = cle.binary_and
def fitness(test, reference):
"""
Determina qué tan correcta es una segmentación de prueba dada.
Como métrica usamos el índice de Jaccard.
Suposición: test es una imagen binaria (0=Falso y 1=Verdadero) y
reference es una imagen con 0=desconocido, 1=Falso, 2=Verdadero.
"""
negative_reference = reference == 1
positive_reference = reference == 2
negative_test = test == 0
positive_test = test == 1
# verdadero positivo: test = 1, ref = 2
tp = binary_and(positive_reference, positive_test).sum()
# verdadero negativo:
tn = binary_and(negative_reference, negative_test).sum()
# falso positivo
fp = binary_and(negative_reference, positive_test).sum()
# falso negativo
fn = binary_and(positive_reference, negative_test).sum()
# devuelve el Índice de Jaccard
return tp / (tp + fn + fp)
fitness(test, annotation)
0.74251497
También deberíamos probar esta función en un rango de parámetros.
sigma = 5
for threshold in range(70, 180, 10):
test = workflow(blobs, sigma, threshold)
print(threshold, fitness(test, annotation))
70 0.49048626
80 0.5843038
90 0.67019403
100 0.74251497
110 0.8183873
120 0.8378158
130 0.79089373
140 0.7024014
150 0.60603446
160 0.49827588
170 0.3974138
A continuación, definimos una función fun que toma solo parámetros numéricos que deben ser optimizados.
def fun(x):
# aplica la configuración de parámetros actual
test = workflow(blobs, x[0], x[1])
# como estamos minimizando, multiplicamos el fitness por -1
return -fitness(test, annotation)
Antes de iniciar la optimización, el paso final es configurar el punto de inicio x0 para la optimización y el criterio de parada atol, el valor de tolerancia absoluta.
# punto de inicio en el espacio de parámetros
x0 = np.array([5, 100])
# ejecuta la optimización
result = minimize(fun, x0, method='nelder-mead', options={'xatol': 1e-3})
result
final_simplex: (array([[ 3.89501953, 121.94091797],
[ 3.89498663, 121.9409585 ],
[ 3.89500463, 121.9403702 ]]), array([-0.85761315, -0.85761315, -0.85761315]))
fun: -0.8576131463050842
message: 'Optimization terminated successfully.'
nfev: 65
nit: 22
status: 0
success: True
x: array([ 3.89501953, 121.94091797])
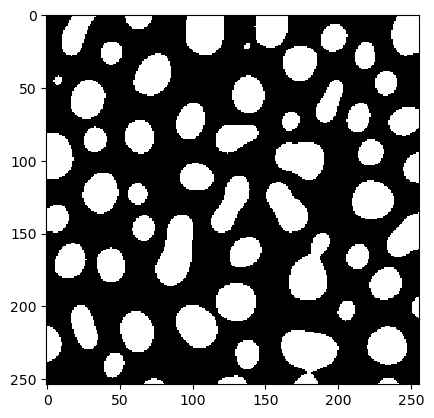
De este objeto result podemos leer el conjunto de parámetros que se ha determinado como óptimo y producir una imagen binaria.
x = result['x']
best_binary = workflow(blobs, x[0], x[1])
cle.imshow(best_binary)
Una nota sobre la convergencia#
Los algoritmos de optimización pueden no siempre encontrar el óptimo global. El éxito depende del punto de inicio de la optimización, de la forma del espacio de parámetros y del algoritmo elegido. En el siguiente ejemplo, demostramos cómo puede verse una optimización fallida si el punto de inicio se eligió mal.
# punto de inicio en el espacio de parámetros
x0 = np.array([0, 60])
# ejecuta la optimización
result = minimize(fun, x0, method='nelder-mead', options={'xatol': 1e-3})
result
final_simplex: (array([[0.00000000e+00, 6.00000000e+01],
[6.10351563e-08, 6.00000000e+01],
[0.00000000e+00, 6.00007324e+01]]), array([-0.63195992, -0.63195992, -0.63195992]))
fun: -0.6319599151611328
message: 'Optimization terminated successfully.'
nfev: 51
nit: 13
status: 0
success: True
x: array([ 0., 60.])
Solución de problemas: Explorando el espacio de parámetros#
En este caso, el conjunto resultante de parámetros no es diferente del punto de inicio. En caso de que el fitness no cambie alrededor del punto de inicio, el algoritmo de optimización no sabe cómo mejorar el resultado. Visualizar los valores alrededor del punto de inicio puede ayudar.
sigma = 0
for threshold in range(57, 63):
test = workflow(blobs, sigma, threshold)
print(threshold, fitness(test, annotation))
57 0.6319599
58 0.6319599
59 0.6319599
60 0.6319599
61 0.6319599
62 0.6319599
threshold = 60
for sigma in np.arange(0, 0.5, 0.1):
test = workflow(blobs, sigma, threshold)
print(sigma, fitness(test, annotation))
0.0 0.6319599
0.1 0.6319599
0.2 0.6319599
0.30000000000000004 0.6319599
0.4 0.6319599
Por lo tanto, tiene sentido realizar alguna exploración manual del espacio de parámetros antes de ejecutar la optimización automática.