(machine_learning_basics.scaling=)
Escalado#
Cuando se utilizan algoritmos de aprendizaje automático para procesar datos, el rango de los parámetros es crucial. Para obtener diferentes parámetros en el mismo rango, puede ser necesario el escalado.
Ver también
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# local import; this library is located in the same folder as the notebook
from data_generator import generate_biomodal_2d_data
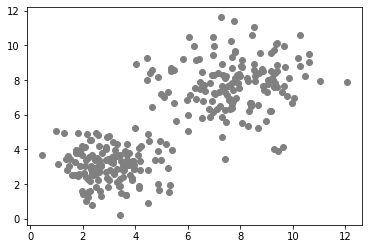
data1 = generate_biomodal_2d_data()
plt.scatter(data1[:, 0], data1[:, 1], c='grey')
<matplotlib.collections.PathCollection at 0x7f79e40aeca0>
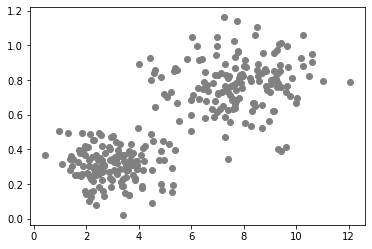
data2 = generate_biomodal_2d_data()
data2[:, 1] = data2[:, 1] * 0.1
plt.scatter(data2[:, 0], data2[:, 1], c='grey')
<matplotlib.collections.PathCollection at 0x7f7980026b80>
Agrupación de datos en diferentes rangos#
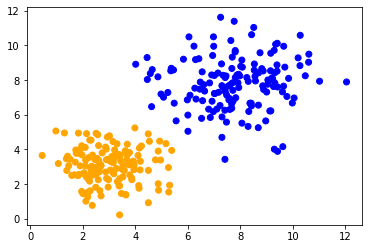
Ahora agruparemos los dos conjuntos de datos aparentemente similares utilizando agrupación k-means. El efecto también se puede observar al usar otros algoritmos. Para asegurarnos de que aplicamos el mismo algoritmo usando la misma configuración a ambos conjuntos de datos, lo encapsulamos en una función y lo reutilizamos.
def classify_and_plot(data):
number_of_classes = 2
classifier = KMeans(n_clusters=number_of_classes)
classifier.fit(data)
prediction = classifier.predict(data)
colors = ['orange', 'blue']
predicted_colors = [colors[i] for i in prediction]
plt.scatter(data[:, 0], data[:, 1], c=predicted_colors)
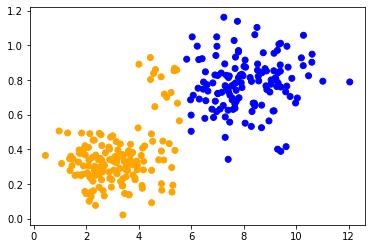
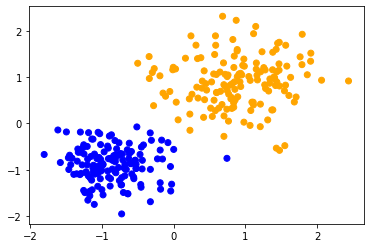
Al aplicar el mismo método a ambos conjuntos de datos, podemos observar que los puntos de datos en el centro se clasifican de manera diferente. La única diferencia entre los conjuntos de datos es su rango de datos. Los puntos de datos están escalados de manera diferente a lo largo de un eje.
classify_and_plot(data1)
classify_and_plot(data2)
Escalado Estándar#
El escalado estándar es una técnica para cambiar el rango de los datos a un rango fijo, por ejemplo, [0, 1]. Permite obtener resultados idénticos en caso de datos que estaban en diferentes rangos.
def scale(data):
scaler = StandardScaler().fit(data)
return scaler.transform(data)
scaled_data1 = scale(data1)
classify_and_plot(scaled_data1)
scaled_data2 = scale(data2)
classify_and_plot(scaled_data2)