Paralelización usando numba#
En este notebook optimizaremos el tiempo de ejecución de un algoritmo utilizando numba.
import time
import numpy as np
from functools import partial
import timeit
import matplotlib.pyplot as plt
import platform
image = np.zeros((10, 10))
Evaluación comparativa del tiempo de ejecución#
En el procesamiento de imágenes, es muy común que el tiempo de ejecución de los algoritmos muestre diferentes patrones dependiendo del tamaño de la imagen. Ahora evaluaremos el rendimiento del algoritmo anterior y veremos cómo se comporta con imágenes de diferentes tamaños. Para vincular una función a evaluar con una imagen dada sin ejecutarla, estamos utilizando el patrón partial.
def benchmark(target_function):
"""
Tests a function on a couple of image sizes and returns times taken for processing.
"""
sizes = np.arange(1, 5) * 10
benchmark_data = []
for size in sizes:
print("Size", size)
# make new data
image = np.zeros((size, size))
# bind target function to given image
partial_function = partial(target_function, image)
# measure execution time
time_in_s = timeit.timeit(partial_function, number=10)
print("time", time_in_s, "s")
# store results
benchmark_data.append([size, time_in_s])
return np.asarray(benchmark_data)
Este es el algoritmo que nos gustaría optimizar:
def silly_sum(image):
# Silly algorithm for wasting compute time
sum = 0
for i in range(image.shape[1]):
for j in range(image.shape[0]):
for k in range(image.shape[0]):
for l in range(image.shape[0]):
sum = sum + image[i,j] - k + l
sum = sum + i
image[i, j] = sum / image.shape[1] / image.shape[0]
benchmark_data_silly_sum = benchmark(silly_sum)
Size 10
time 0.026225900000000024 s
Size 20
time 0.3880397999999996 s
Size 30
time 2.4635917000000003 s
Size 40
time 6.705509999999999 s
plt.scatter(benchmark_data_silly_sum[:,0] ** 2, benchmark_data_silly_sum[:,1])
plt.legend(["normal"])
plt.xlabel("Tamaño de imagen en píxeles")
plt.ylabel("Tiempo de cómputo en s")
plt.show()
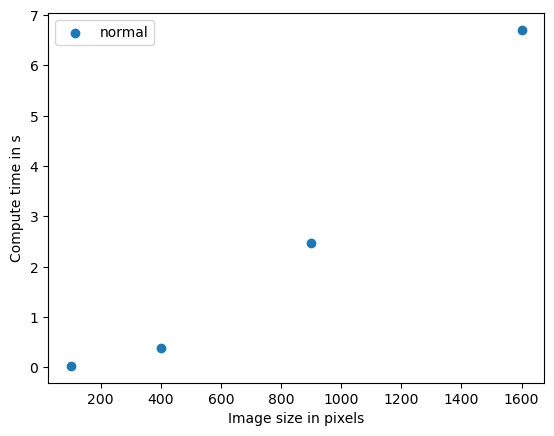
Este algoritmo depende fuertemente del tamaño de la imagen, el gráfico muestra una complejidad aproximadamente cuadrática. Esto significa que si el tamaño de los datos se duplica, el tiempo de cómputo se multiplica por cuatro. La notación O del algoritmo es O(n^2). Podríamos suponer que un algoritmo similar aplicado en 3D tiene una complejidad cúbica, O(n^3). Si tales algoritmos son cuellos de botella en tu ciencia, la paralelización y la aceleración por GPU tienen mucho sentido.
Optimización de código usando numba#
En caso de que el código que ejecutemos sea simple y solo use funciones estándar de Python, numpy, etc., podemos usar un compilador just-in-time (JIT), por ejemplo, proporcionado por numba para acelerar el código.
from numba import jit
@jit
def process_image_compiled(image):
for x in range(image.shape[1]):
for y in range(image.shape[1]):
# Silly algorithm for wasting compute time
sum = 0
for i in range(1000):
for j in range(1000):
sum = sum + x
sum = sum + y
image[x, y] = sum
%timeit process_image_compiled(image)
The slowest run took 56.00 times longer than the fastest. This could mean that an intermediate result is being cached.
2.84 µs ± 5.7 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)