Clasificación de píxeles usando Scikit-learn#
La clasificación de píxeles es una técnica para asignar píxeles a múltiples clases. Si hay dos clases (objeto y fondo), estamos hablando de binarización. En este ejemplo usamos un clasificador de bosque aleatorio para la clasificación de píxeles.
Ver también
from sklearn.ensemble import RandomForestClassifier
from skimage.io import imread, imshow
import numpy as np
import napari
Como imagen de ejemplo, use el conjunto de imágenes BBBC038v1, disponible en la Broad Bioimage Benchmark Collection Caicedo et al., Nature Methods, 2019.
image = imread('../../data/BBBC038/0bf4b1.tif')
imshow(image)
<matplotlib.image.AxesImage at 0x7f817af51ac0>
Para demostrar cómo funciona el algoritmo, anotamos dos pequeñas regiones en la parte izquierda de la imagen con valores 1 y 2 para el fondo y el primer plano (objetos).
annotation = np.zeros(image.shape)
annotation[0:10,0:10] = 1
annotation[45:55,10:20] = 2
imshow(annotation, vmin=0, vmax=2)
/Users/haase/opt/anaconda3/envs/bio_39/lib/python3.9/site-packages/skimage/io/_plugins/matplotlib_plugin.py:150: UserWarning: Low image data range; displaying image with stretched contrast.
lo, hi, cmap = _get_display_range(image)
/Users/haase/opt/anaconda3/envs/bio_39/lib/python3.9/site-packages/skimage/io/_plugins/matplotlib_plugin.py:150: UserWarning: Float image out of standard range; displaying image with stretched contrast.
lo, hi, cmap = _get_display_range(image)
<matplotlib.image.AxesImage at 0x7f81180937c0>
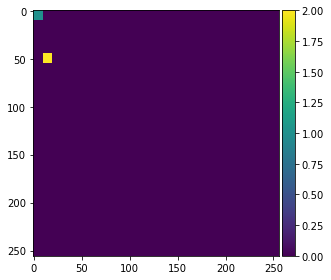
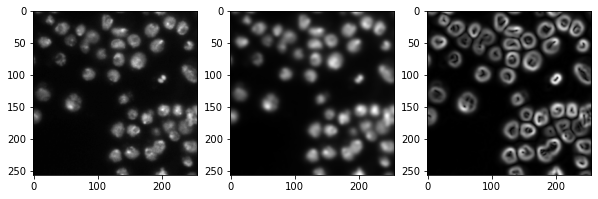
Generando un stack de características#
Los clasificadores de píxeles como el clasificador de bosque aleatorio toman múltiples imágenes como entrada. Típicamente llamamos a estas imágenes un stack de características porque ahora existen múltiples valores (características) para cada píxel. En el siguiente ejemplo creamos un stack de características que contiene tres características:
El valor original del píxel
El valor del píxel después de un desenfoque gaussiano
El valor del píxel de la imagen desenfocada gaussiana procesada a través de un operador Sobel.
Así, eliminamos el ruido de la imagen y detectamos bordes. Las tres imágenes sirven al clasificador de píxeles para diferenciar píxeles positivos y negativos.
from skimage import filters
def generate_feature_stack(image):
# determine features
blurred = filters.gaussian(image, sigma=2)
edges = filters.sobel(blurred)
# collect features in a stack
# The ravel() function turns a nD image into a 1-D image.
# We need to use it because scikit-learn expects values in a 1-D format here.
feature_stack = [
image.ravel(),
blurred.ravel(),
edges.ravel()
]
# return stack as numpy-array
return np.asarray(feature_stack)
feature_stack = generate_feature_stack(image)
# show feature images
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 3, figsize=(10,10))
# reshape(image.shape) is the opposite of ravel() here. We just need it for visualization.
axes[0].imshow(feature_stack[0].reshape(image.shape), cmap=plt.cm.gray)
axes[1].imshow(feature_stack[1].reshape(image.shape), cmap=plt.cm.gray)
axes[2].imshow(feature_stack[2].reshape(image.shape), cmap=plt.cm.gray)
<matplotlib.image.AxesImage at 0x7f817b16d5e0>
Formateando datos#
Ahora necesitamos formatear los datos de entrada para que se ajusten a lo que scikit learn espera. Scikit-learn pide un array de forma (n, m) como datos de entrada y (n) anotaciones. n corresponde al número de píxeles y m al número de características. En nuestro caso m = 3.
def format_data(feature_stack, annotation):
# reformat the data to match what scikit-learn expects
# transpose the feature stack
X = feature_stack.T
# make the annotation 1-dimensional
y = annotation.ravel()
# remove all pixels from the feature and annotations which have not been annotated
mask = y > 0
X = X[mask]
y = y[mask]
return X, y
X, y = format_data(feature_stack, annotation)
print("input shape", X.shape)
print("annotation shape", y.shape)
input shape (200, 3)
annotation shape (200,)
Entrenando el clasificador de bosque aleatorio#
Ahora entrenamos el clasificador de bosque aleatorio proporcionando el stack de características X y las anotaciones y.
classifier = RandomForestClassifier(max_depth=2, random_state=0)
classifier.fit(X, y)
RandomForestClassifier(max_depth=2, random_state=0)
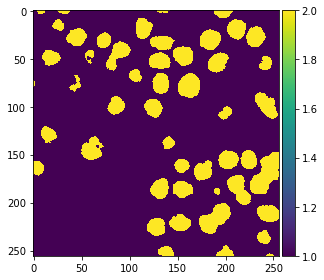
Prediciendo clases de píxeles#
Después de que el clasificador ha sido entrenado, podemos usarlo para predecir clases de píxeles para imágenes completas. Nota en el siguiente código, proporcionamos feature_stack.T que son más píxeles que X en los comandos anteriores, porque también contiene los píxeles que no fueron anotados antes.
res = classifier.predict(feature_stack.T) - 1 # we subtract 1 to make background = 0
imshow(res.reshape(image.shape))
<matplotlib.image.AxesImage at 0x7f817b59fd90>

Segmentación interactiva#
También podemos usar napari para anotar algunas regiones como negativas (etiqueta = 1) y positivas (etiqueta = 2).
# start napari
viewer = napari.Viewer()
# add image
viewer.add_image(image)
# add an empty labels layer and keet it in a variable
labels = viewer.add_labels(np.zeros(image.shape).astype(int))
/Users/haase/opt/anaconda3/envs/bio_39/lib/python3.9/site-packages/napari_tools_menu/__init__.py:165: FutureWarning: Public access to Window.qt_viewer is deprecated and will be removed in
v0.5.0. It is considered an "implementation detail" of the napari
application, not part of the napari viewer model. If your use case
requires access to qt_viewer, please open an issue to discuss.
self.tools_menu = ToolsMenu(self, self.qt_viewer.viewer)
Continúe después de anotar al menos dos regiones con etiquetas 1 y 2.
Tome una captura de pantalla de la anotación:
napari.utils.nbscreenshot(viewer)

Recupere las anotaciones de la capa de napari:
manual_annotations = labels.data
imshow(manual_annotations, vmin=0, vmax=2)
/Users/haase/opt/anaconda3/envs/bio_39/lib/python3.9/site-packages/skimage/io/_plugins/matplotlib_plugin.py:150: UserWarning: Low image data range; displaying image with stretched contrast.
lo, hi, cmap = _get_display_range(image)
<matplotlib.image.AxesImage at 0x7f8158e05a30>

Como hemos usado funciones en el ejemplo anterior, podemos simplemente repetir el mismo procedimiento con las anotaciones manuales.
# generate features (that's actually not necessary,
# as the variable is still there and the image is the same.
# but we do it for completeness)
feature_stack = generate_feature_stack(image)
X, y = format_data(feature_stack, manual_annotations)
# train classifier
classifier = RandomForestClassifier(max_depth=2, random_state=0)
classifier.fit(X, y)
# process the whole image and show result
result_1d = classifier.predict(feature_stack.T)
result_2d = result_1d.reshape(image.shape)
imshow(result_2d)
/Users/haase/opt/anaconda3/envs/bio_39/lib/python3.9/site-packages/skimage/io/_plugins/matplotlib_plugin.py:150: UserWarning: Low image data range; displaying image with stretched contrast.
lo, hi, cmap = _get_display_range(image)
<matplotlib.image.AxesImage at 0x7f8138dea5e0>
También agregamos el resultado a napari.
viewer.add_labels(result_2d)
<Labels layer 'result_2d' at 0x7f816a1faaf0>
napari.utils.nbscreenshot(viewer)

Ejercicio#
Cambie el código para que pueda anotar tres regiones diferentes:
Núcleos
Fondo
Los bordes entre los blobs y el fondo