Paralelización#
Al programar algoritmos personalizados en Python, puede suceder que nuestro código se vuelva lento porque ejecutamos un par de bucles for anidados. Si los bucles internos no dependen entre sí, el código se puede paralelizar y acelerar. Ten en cuenta que estamos paralelizando código en una unidad central de procesamiento (CPU) y no lo confundas con la aceleración por GPU que utiliza unidades de procesamiento gráfico (GPUs).
Ver también
import time
import numpy as np
from functools import partial
import timeit
import matplotlib.pyplot as plt
import platform
Comenzamos con un algoritmo que hace algo con una imagen en coordenadas de píxeles dadas
def slow_thing(image, x, y):
# Silly algorithm for wasting compute time
sum = 0
for i in range(1000):
for j in range(100):
sum = sum + x
sum = sum + y
image[x, y] = sum
image = np.zeros((10, 10))
Ahora usamos timeit para medir cuánto tiempo tarda la operación en procesar un solo píxel.
%timeit slow_thing(image, 4, 5)
3.3 ms ± 395 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Ahora definimos la operación en toda la imagen y medimos el tiempo de esta función.
def process_image(image):
for x in range(image.shape[1]):
for y in range(image.shape[1]):
slow_thing(image, x, y)
%timeit process_image(image)
353 ms ± 42.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Esta función es bastante lenta y la paralelización puede tener sentido.
Paralelización usando joblib.Parallel#
Un enfoque simple y directo para la paralelización es usar joblib.Parallel y joblib.delayed.
from joblib import Parallel, delayed, cpu_count
Ten en cuenta la escritura inversa de los bucles for en el siguiente bloque. El término delayed(slow_thing)(image, x, y) es técnicamente una llamada a función que no se ejecuta. Más tarde, cuando realmente se necesita el valor de retorno de esta llamada, entonces ocurrirá la ejecución real. Consulta dask delayed para más detalles.
def process_image_parallel(image):
Parallel(n_jobs=-1)(delayed(slow_thing)(image, x, y)
for y in range(image.shape[0])
for x in range(image.shape[1]))
%timeit process_image_parallel(image)
62.4 ms ± 218 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
Una aceleración de 7 no está mal. El n_jobs=-1 implica que se utilizan todas las unidades de cómputo / hilos. También podemos imprimir cuántos núcleos de cómputo se utilizaron:
cpu_count()
16
Para fines de documentación, también podemos imprimir en qué tipo de CPU se ejecutó ese algoritmo. Esta cadena puede ser más o menos informativa dependiendo del sistema operativo / computadora en el que estemos ejecutando este notebook.
platform.processor()
'AMD64 Family 25 Model 68 Stepping 1, AuthenticAMD'
Benchmarking del tiempo de ejecución#
En procesamiento de imágenes, es muy común que el tiempo de ejecución de los algoritmos muestre diferentes patrones dependiendo del tamaño de la imagen. Ahora haremos un benchmark del algoritmo anterior y veremos cómo se comporta con imágenes de diferentes tamaños. Para vincular una función a benchmark a una imagen dada sin ejecutarla, estamos usando el patrón partial.
def benchmark(target_function):
"""
Tests a function on a couple of image sizes and returns times taken for processing.
"""
sizes = np.arange(1, 5) * 10
benchmark_data = []
for size in sizes:
print("Size", size)
# make new data
image = np.zeros((size, size))
# bind target function to given image
partial_function = partial(target_function, image)
# measure execution time
time_in_s = timeit.timeit(partial_function, number=10)
print("time", time_in_s, "s")
# store results
benchmark_data.append([size, time_in_s])
return np.asarray(benchmark_data)
print("Benchmarking normal")
benchmark_data_normal = benchmark(process_image)
print("Benchmarking parallel")
benchmark_data_parallel = benchmark(process_image_parallel)
Benchmarking normal
Size 10
time 3.5427859 s
Size 20
time 13.8465019 s
Size 30
time 30.883478699999998 s
Size 40
time 55.4255712 s
Benchmarking parallel
Size 10
time 0.7873560999999967 s
Size 20
time 2.0985788000000127 s
Size 30
time 4.9782009000000045 s
Size 40
time 7.9171936000000045 s
plt.scatter(benchmark_data_normal[:,0] ** 2, benchmark_data_normal[:,1])
plt.scatter(benchmark_data_parallel[:,0] ** 2, benchmark_data_parallel[:,1])
plt.legend(["normal", "parallel"])
plt.xlabel("Image size in pixels")
plt.ylabel("Compute time in s")
plt.show()
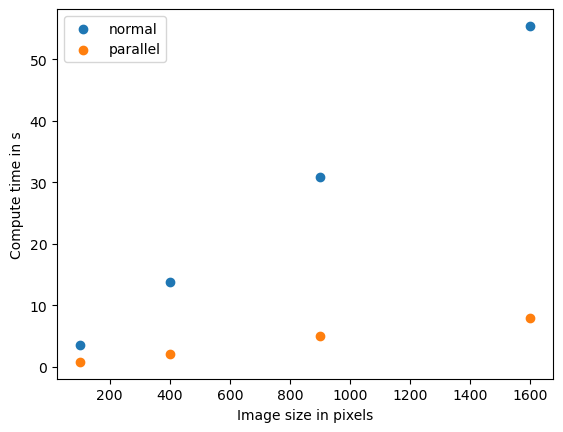
Si vemos este patrón, hablamos de una relación lineal entre el tamaño de los datos y el tiempo de cómputo. Los científicos de la computación utilizan la notación O para describir la complejidad de los algoritmos. Este algoritmo tiene O(n) y n representa el número de píxeles en este caso.
Garantía de calidad#
Ten en cuenta que en esta sección solo medimos el tiempo de cómputo de los algoritmos. No determinamos si las diferentes versiones optimizadas de los algoritmos producen el mismo resultado. La garantía de calidad es una buena práctica científica. Lo mismo es relevante en el contexto de la aceleración por GPU y, por ejemplo, se describe en detalle aquí.