Aprendizaje automático no supervisado#
El aprendizaje automático no supervisado es una técnica para configurar (aprender) parámetros de un modelo computacional basado en ninguna anotación, pero con información adicional como el número de categorías a diferenciar. Muchos algoritmos en esta categoría realizan agrupación de datos.
Ver también
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.cluster import KMeans
# local import; this library is located in the same folder as the notebook
from data_generator import generate_biomodal_2d_data
Nuestro punto de partida para demostrar el aprendizaje automático supervisado es un par de mediciones en una distribución bimodal. En el siguiente conjunto de datos, los objetos con un área más grande suelen ser también más alargados.
data = generate_biomodal_2d_data()
plt.scatter(data[:, 0], data[:, 1], c='grey')
<matplotlib.collections.PathCollection at 0x7fd53c2d7c70>
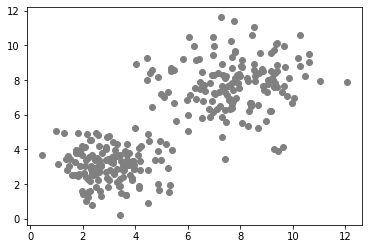
En el caso de algoritmos de aprendizaje automático no supervisado, necesitamos proporcionar información adicional al algoritmo para que pueda separar (agrupar) los puntos de datos en regiones de manera significativa. La información que proporcionamos depende del algoritmo y de la distribución de los datos. Típicamente, seleccionamos el algoritmo dependiendo de los datos. En el ejemplo anterior, podemos ver claramente dos grupos, es una distribución bimodal. En ese caso, podemos especificar el número de clases a diferenciar:
number_of_classes = 2
Inicializando la agrupación k-means#
La agrupación k-means es un algoritmo que agrupa puntos de datos en k grupos de modo que todos los puntos de datos se asignan al centro más cercano de los grupos.
Los algoritmos de agrupación en scikit-learn típicamente tienen una función fit() que consume un conjunto de data como el dado anteriormente.
classifier = KMeans(n_clusters=number_of_classes)
classifier.fit(data)
KMeans(n_clusters=2)
Predicción#
Después de que el modelo está entrenado (o ajustado), podemos aplicarlo a nuestros datos para obtener una predicción de a qué grupo pertenecen los puntos de datos. La indexación de los grupos comienza en 0. Por lo tanto, si pedimos diferenciar dos grupos, los índices de los grupos son 0 y 1:
prediction = classifier.predict(data)
prediction
array([0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0,
0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0,
1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 1,
1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0,
1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1,
0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1,
1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0,
0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1,
0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0,
0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1,
0, 0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0,
0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 1, 0, 1,
1, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1], dtype=int32)
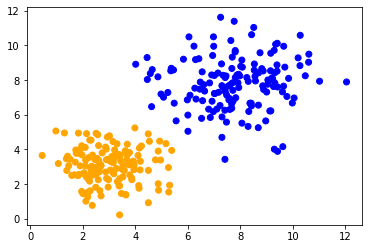
Luego podemos visualizar todas las clases predichas en colores.
colors = ['orange', 'blue']
predicted_colors = [colors[i] for i in prediction]
plt.scatter(data[:, 0], data[:, 1], c=predicted_colors)
<matplotlib.collections.PathCollection at 0x7fd4d8018d30>
Ejercicio#
Entrena un Modelo de Mezcla Gaussiana y visualiza su predicción.
from sklearn.mixture import GaussianMixture
classifier = GaussianMixture(n_components=2)