Avance: Análisis de bioimágenes con Python#
En los siguientes capítulos nos adentraremos en el análisis de imágenes, aprendizaje automático y bioestadística utilizando Python. Este primer cuaderno sirve como un avance de lo que haremos.
Los cuadernos de Python típicamente comienzan con las importaciones de las bibliotecas de Python que el cuaderno utilizará. El lector puede verificar primero si todas esas bibliotecas están instaladas antes de revisar todo el cuaderno.
import numpy as np
from skimage.io import imread, imshow
import pyclesperanto_prototype as cle
from skimage import measure
import pandas as pd
import seaborn
import apoc
import stackview
Trabajando con datos de imágenes#
Comenzamos cargando los datos de imagen de interés. En este ejemplo, cargamos una imagen que muestra un ojo de pez cebra, cortesía de Mauricio Rocha Martins, laboratorio Norden, MPI CBG Dresden.
# open an image file
multichannel_image = imread("../../data/zfish_eye.tif")
# extract a channel
single_channel_image = multichannel_image[:,:,0]
cropped_image = single_channel_image[200:600, 500:900]
stackview.insight(cropped_image)

|

|
Filtrado de imágenes#
Un paso común al trabajar con imágenes de microscopía de fluorescencia es restar la intensidad de fondo, por ejemplo, resultante de la luz fuera de foco. Esto puede mejorar los resultados de la segmentación de imágenes más adelante en el flujo de trabajo.
# subtract background using a top-hat filter
background_subtracted_image = cle.top_hat_box(cropped_image, radius_x=20, radius_y=20)
stackview.insight(background_subtracted_image)

|

|
Segmentación de imágenes#
Para segmentar los núcleos en la imagen dada, existe un gran número de algoritmos. Aquí usamos un enfoque clásico llamado Etiquetado Voronoi-Otsu, que ciertamente no es perfecto.
label_image = np.asarray(cle.voronoi_otsu_labeling(background_subtracted_image, spot_sigma=4))
# show result
stackview.insight(label_image)

|
|
Mediciones y extracción de características#
Después de que la imagen es segmentada, podemos medir propiedades de los objetos individuales. Esas propiedades son típicamente parámetros estadísticos descriptivos, llamados características. Cuando derivamos mediciones como el área o la intensidad media, extraemos esas dos características.
statistics = measure.regionprops_table(label_image,
intensity_image=cropped_image,
properties=('area', 'mean_intensity', 'major_axis_length', 'minor_axis_length'))
Trabajando con tablas#
El objeto statistics creado anteriormente contiene una estructura de datos de Python, un diccionario de vectores de medición, que no es lo más intuitivo de ver. Por lo tanto, lo convertimos en una tabla. Los científicos de datos a menudo llaman a estas tablas DataFrames, que están disponibles en la biblioteca pandas.
dataframe = pd.DataFrame(statistics)
Podemos usar columnas de tabla existentes para calcular otras mediciones, como la relación de aspecto.
dataframe['aspect_ratio'] = dataframe['major_axis_length'] / dataframe['minor_axis_length']
dataframe
| area | mean_intensity | major_axis_length | minor_axis_length | aspect_ratio | |
|---|---|---|---|---|---|
| 0 | 294.0 | 36604.625850 | 25.656180 | 18.800641 | 1.364644 |
| 1 | 91.0 | 37379.769231 | 20.821990 | 6.053507 | 3.439658 |
| 2 | 246.0 | 44895.308943 | 21.830827 | 14.916032 | 1.463581 |
| 3 | 574.0 | 44394.637631 | 37.788705 | 19.624761 | 1.925563 |
| 4 | 518.0 | 45408.903475 | 26.917447 | 24.872908 | 1.082199 |
| ... | ... | ... | ... | ... | ... |
| 108 | 568.0 | 48606.121479 | 37.357606 | 19.808121 | 1.885974 |
| 109 | 175.0 | 25552.074286 | 17.419031 | 13.675910 | 1.273702 |
| 110 | 460.0 | 39031.419565 | 26.138592 | 23.522578 | 1.111213 |
| 111 | 407.0 | 39343.292383 | 28.544027 | 19.563792 | 1.459023 |
| 112 | 31.0 | 29131.322581 | 6.892028 | 5.711085 | 1.206781 |
113 rows × 5 columns
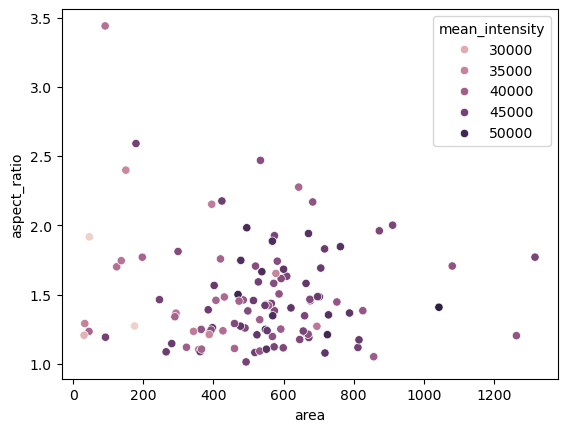
Gráficos#
Las mediciones se pueden visualizar utilizando gráficos.
seaborn.scatterplot(dataframe, x='area', y='aspect_ratio', hue='mean_intensity')
<Axes: xlabel='area', ylabel='aspect_ratio'>
Estadísticas descriptivas#
Tomando esta tabla como punto de partida, podemos usar estadísticas para obtener una visión general de los datos medidos.
mean_area = np.mean(dataframe['area'])
stddev_area = np.std(dataframe['area'])
print("El área media del núcleo es", mean_area, "+-", stddev_area, "píxeles")
Mean nucleus area is 524.4247787610619 +- 231.74703195433014 pixels
Clasificación#
Para comprender mejor la estructura interna de los tejidos, pero también para corregir artefactos en los flujos de trabajo de procesamiento de imágenes, podemos clasificar las células, por ejemplo, según su tamaño y forma.
object_classifier = apoc.ObjectClassifier('../../data/blobs_classifier.cl')
classification_image = object_classifier.predict(label_image, cropped_image)
stackview.imshow(classification_image)
