Análisis cuantitativo de imágenes#
Después de segmentar y etiquetar objetos en una imagen, podemos medir propiedades de estos objetos.
Ver también
Antes de poder hacer mediciones, necesitamos una imagen y una imagen_etiquetada correspondiente. Por lo tanto, recapitulamos el filtrado, umbralización y etiquetado:
from skimage.io import imread
from skimage import filters
from skimage import measure
from pyclesperanto_prototype import imshow
import pandas as pd
import numpy as np
# load image
image = imread("../../data/blobs.tif")
# denoising
blurred_image = filters.gaussian(image, sigma=1)
# binarization
threshold = filters.threshold_otsu(blurred_image)
thresholded_image = blurred_image >= threshold
# labeling
label_image = measure.label(thresholded_image)
# visualization
imshow(label_image, labels=True)
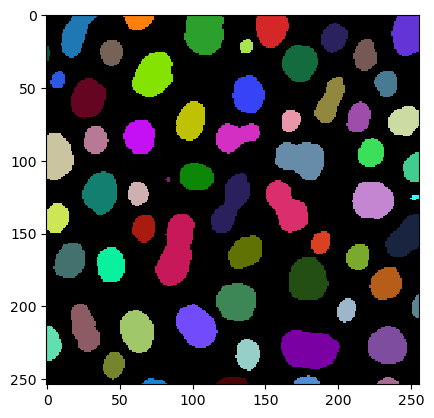
Mediciones / propiedades de la región#
Para leer las propiedades de las regiones, usamos la función regionprops:
# analyse objects
properties = measure.regionprops(label_image, intensity_image=image)
Los resultados se almacenan como objetos RegionProps, que no son muy informativos:
properties[0:5]
[<skimage.measure._regionprops.RegionProperties at 0x1c272b8f8e0>,
<skimage.measure._regionprops.RegionProperties at 0x1c26d278af0>,
<skimage.measure._regionprops.RegionProperties at 0x1c26d2784c0>,
<skimage.measure._regionprops.RegionProperties at 0x1c26d278b20>,
<skimage.measure._regionprops.RegionProperties at 0x1c26d278b80>]
Si estás interesado en qué propiedades medimos: Están listadas en la documentación de la función measure.regionprops. Básicamente, ahora tenemos una variable properties que contiene 40 características diferentes. Pero solo estamos interesados en un pequeño subconjunto de ellas.
Por lo tanto, podemos reorganizar las mediciones en un diccionario que contiene matrices con nuestras características de interés:
statistics = {
'area': [p.area for p in properties],
'mean': [p.mean_intensity for p in properties],
'major_axis': [p.major_axis_length for p in properties],
'minor_axis': [p.minor_axis_length for p in properties]
}
Leer esos diccionarios de matrices no es muy conveniente. Para eso introducimos los DataFrames de pandas que son comúnmente utilizados por los científicos de datos. “DataFrames” es solo otro término para “tablas” utilizado en Python.
df = pd.DataFrame(statistics)
df
| area | mean | major_axis | minor_axis | |
|---|---|---|---|---|
| 0 | 429 | 191.440559 | 34.779230 | 16.654732 |
| 1 | 183 | 179.846995 | 20.950530 | 11.755645 |
| 2 | 658 | 205.604863 | 30.198484 | 28.282790 |
| 3 | 433 | 217.515012 | 24.508791 | 23.079220 |
| 4 | 472 | 213.033898 | 31.084766 | 19.681190 |
| ... | ... | ... | ... | ... |
| 57 | 213 | 184.525822 | 18.753879 | 14.468993 |
| 58 | 79 | 184.810127 | 18.287489 | 5.762488 |
| 59 | 88 | 182.727273 | 21.673692 | 5.389867 |
| 60 | 52 | 189.538462 | 14.335104 | 5.047883 |
| 61 | 48 | 173.833333 | 16.925660 | 3.831678 |
62 rows × 4 columns
También puedes agregar columnas personalizadas calculando tu propia métrica, por ejemplo, la relación_de_aspecto:
df['aspect_ratio'] = [p.major_axis_length / p.minor_axis_length for p in properties]
df
| area | mean | major_axis | minor_axis | aspect_ratio | |
|---|---|---|---|---|---|
| 0 | 429 | 191.440559 | 34.779230 | 16.654732 | 2.088249 |
| 1 | 183 | 179.846995 | 20.950530 | 11.755645 | 1.782168 |
| 2 | 658 | 205.604863 | 30.198484 | 28.282790 | 1.067734 |
| 3 | 433 | 217.515012 | 24.508791 | 23.079220 | 1.061942 |
| 4 | 472 | 213.033898 | 31.084766 | 19.681190 | 1.579415 |
| ... | ... | ... | ... | ... | ... |
| 57 | 213 | 184.525822 | 18.753879 | 14.468993 | 1.296143 |
| 58 | 79 | 184.810127 | 18.287489 | 5.762488 | 3.173540 |
| 59 | 88 | 182.727273 | 21.673692 | 5.389867 | 4.021193 |
| 60 | 52 | 189.538462 | 14.335104 | 5.047883 | 2.839825 |
| 61 | 48 | 173.833333 | 16.925660 | 3.831678 | 4.417297 |
62 rows × 5 columns
Estos dataframes se pueden guardar en el disco de manera conveniente:
df.to_csv("blobs_analysis.csv")
Además, se pueden medir propiedades de nuestra tabla statistics usando numpy. Por ejemplo, el área media:
# measure mean area
np.mean(df['area'])
355.3709677419355
Ejercicios#
Analiza la imagen de blobs cargada.
¿Cuántos objetos hay en ella?
¿Qué tamaño tiene el objeto más grande?
¿Cuáles son la media y la desviación estándar de la imagen?
¿Cuáles son la media y la desviación estándar del área de los objetos segmentados?