Procesamiento de imágenes en mosaico, una visión rápida#
En este cuaderno procesaremos un gran conjunto de datos que se ha guardado en formato zarr para contar células en mosaicos individuales utilizando dask y zarr. Los principios subyacentes se explicarán en las siguientes secciones.
import zarr
import dask.array as da
import numpy as np
from skimage.io import imread
import pyclesperanto_prototype as cle
from pyclesperanto_prototype import imshow
from numcodecs import Blosc
Para fines de demostración, utilizamos un conjunto de datos proporcionado por Theresa Suckert, OncoRay, Hospital Universitario Carl Gustav Carus, TU Dresden. El conjunto de datos está bajo la Licencia: CC-BY 4.0. Estamos utilizando aquí una versión recortada que se guardó nuevamente como una imagen de 8 bits para poder proporcionarla con el cuaderno. Puedes encontrar la imagen completa de 16 bits en formato de archivo CZI en línea. El contexto biológico se explica en Suckert et al. 2020, donde también aplicamos un flujo de trabajo similar.
Cuando se trabaja con grandes volúmenes de datos, es probable que ya tengas una imagen almacenada en el formato adecuado para comenzar. Para fines de demostración, aquí guardamos una imagen de prueba en el formato zarr, que se usa comúnmente para manejar grandes volúmenes de datos de imágenes.
# Resave a test image into tiled zarr format
input_filename = '../../data/P1_H_C3H_M004_17-cropped.tif'
zarr_filename = '../../data/P1_H_C3H_M004_17-cropped.zarr'
image = imread(input_filename)[1]
compressor = Blosc(cname='zstd', clevel=3, shuffle=Blosc.BITSHUFFLE)
zarray = zarr.array(image, chunks=(100, 100), compressor=compressor)
zarr.convenience.save(zarr_filename, zarray)
Cargando la imagen respaldada por zarr#
Dask tiene soporte integrado para el formato de archivo zarr. Podemos crear arreglos dask directamente desde un archivo zarr.
zarr_image = da.from_zarr(zarr_filename)
zarr_image
|
Podemos aplicar procesamiento de imágenes a este conjunto de datos en mosaico directamente.
Contando núcleos#
Para contar los núcleos, configuramos un simple flujo de trabajo de procesamiento de imágenes. Devuelve una imagen con un solo píxel que contiene el número de núcleos en la imagen de entrada dada. Estos píxeles individuales se ensamblarán en un mapa de recuento de píxeles; una imagen con muchos menos píxeles que la imagen original, pero con la ventaja de que podemos verla - ya no es un conjunto de datos grande.cle.exclude_labels_with_map_values_within_range
def count_nuclei(image):
"""
Label objects in a binary image and produce a pixel-count-map image.
"""
# Count nuclei including those which touch the image border
labels = cle.voronoi_otsu_labeling(image, spot_sigma=3.5)
label_intensity_map = cle.mean_intensity_map(image, labels)
high_intensity_labels = cle.exclude_labels_with_map_values_within_range(label_intensity_map, labels, maximum_value_range=20)
nuclei_count = high_intensity_labels.max()
# Count nuclei including those which touch the image border
labels_without_borders = cle.exclude_labels_on_edges(high_intensity_labels)
nuclei_count_excluding_borders = labels_without_borders.max()
# Both nuclei-count including and excluding nuclei at image borders
# are no good approximation. We should exclude the nuclei only on
# half of the borders to get a good estimate.
# Alternatively, we just take the average of both counts.
result = np.asarray([[(nuclei_count + nuclei_count_excluding_borders) / 2]])
return result
Antes de poder iniciar el cálculo, necesitamos desactivar la ejecución asíncrona de operaciones en pyclesperanto. Ver también el problema relacionado.
cle.set_wait_for_kernel_finish(True)
Para procesar mosaicos usando dask, configuramos bloques de procesamiento sin superposición.
tile_map = da.map_blocks(count_nuclei, zarr_image)
tile_map
|
Como la imagen resultante es mucho más pequeña que la original, podemos calcular todo el mapa de resultados.
result = tile_map.compute()
result.shape
(20, 50)
De nuevo, como el mapa de resultados es pequeño, podemos simplemente visualizarlo.
cle.imshow(result, colorbar=True)
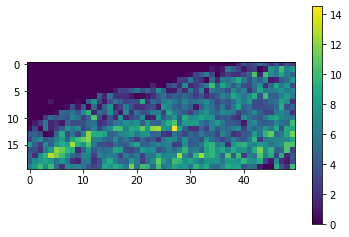
Con una rápida comprobación visual en la imagen original, podemos ver que efectivamente en la esquina superior izquierda de la imagen hay muchas menos células que en la esquina inferior derecha.
cle.imshow(cle.voronoi_otsu_labeling(image, spot_sigma=3.5), labels=True)
