Aprendizaje automático supervisado#
El aprendizaje automático supervisado es una técnica para configurar (aprender) parámetros de un modelo computacional basado en datos anotados. En este ejemplo, proporcionamos datos anotados de manera dispersa, lo que significa que solo anotamos algunos de los puntos de datos dados.
Ver también
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import jaccard_score, accuracy_score, precision_score, recall_score
# local import; this library is located in the same folder as the notebook
from data_generator import generate_biomodal_2d_data
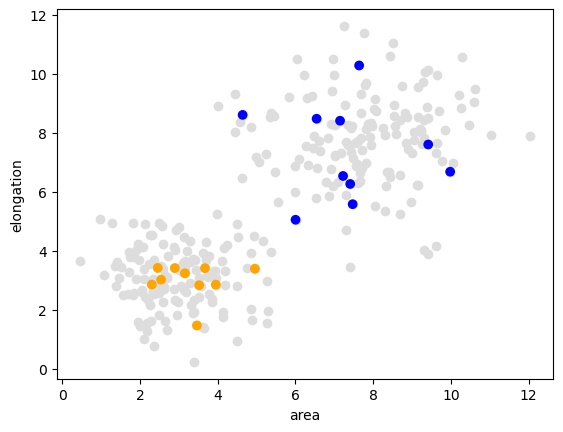
Nuestro punto de partida para demostrar el aprendizaje automático supervisado es un par de mediciones en una distribución bimodal. En el siguiente conjunto de datos, los objetos con un área más grande también suelen ser más alargados.
data = generate_biomodal_2d_data()
# select some data points
data_to_annotate = data[:20]
# manually annotate them
manual_annotation = [1, 1, 2, 1, 1, 1, 2, 2, 1, 1, 2, 1, 1, 2, 1, 2, 2, 2, 2, 2]
# visualize the data
plt.scatter(data[:, 0], data[:, 1], c='#DDDDDD')
plt.xlabel('area')
plt.ylabel('elongation')
colors = ['orange', 'blue']
annotated_colors = [colors[i-1] for i in manual_annotation]
plt.scatter(data_to_annotate[:, 0], data_to_annotate[:, 1], c=annotated_colors)
<matplotlib.collections.PathCollection at 0x1e67dafe220>
Separación de datos de prueba y validación#
Antes de entrenar nuestro clasificador, necesitamos dividir los datos anotados en dos subconjuntos. El objetivo es permitir una validación imparcial. Entrenamos con la primera mitad de los puntos de datos anotados y medimos la calidad en la segunda mitad. Leer más.
train_data = data_to_annotate[:10]
validation_data = data_to_annotate[10:]
train_annotation = manual_annotation[:10]
validation_annotation = manual_annotation[10:]
Entrenamiento del clasificador#
Con los datos seleccionados para anotar y la anotación manual, podemos entrenar un Clasificador de Bosque Aleatorio.
classifier = RandomForestClassifier()
classifier.fit(train_data, train_annotation)
RandomForestClassifier()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomForestClassifier()
Validación#
Ahora podemos aplicar el clasificador a los datos de validación y medir cuántos de estos puntos de datos se han analizado correctamente.
result = classifier.predict(validation_data)
# Show results next to annotation in a table
result_annotation_comparison_table = {
"Predicted": result,
"Annotated": validation_annotation
}
pd.DataFrame(result_annotation_comparison_table)
| Predicted | Annotated | |
|---|---|---|
| 0 | 2 | 2 |
| 1 | 1 | 1 |
| 2 | 1 | 1 |
| 3 | 1 | 2 |
| 4 | 1 | 1 |
| 5 | 2 | 2 |
| 6 | 2 | 2 |
| 7 | 2 | 2 |
| 8 | 2 | 2 |
| 9 | 2 | 2 |
Para obtener algunas medidas estandarizadas de la calidad de los resultados de nuestro clasificador, utilizamos las métricas de scikit-learn. También hay disponible una descripción general de las técnicas en Wikipedia y significan en este contexto:
Precisión: ¿Qué porción de las predicciones fueron correctas?
Precisión: ¿Qué porción de los
1predichos fueron anotados como1?Recall (sensibilidad): ¿Qué porción de los
2predichos han sido anotados como2?
accuracy_score(validation_annotation, result)
0.9
precision_score(validation_annotation, result)
0.75
recall_score(validation_annotation, result)
1.0
Si desea entender más detalladamente cómo se cuentan las entradas y se calculan las puntuaciones de calidad, puede ser útil echar un vistazo a la matriz de confusión multilabel.
Predicción#
Después de entrenar y validar el clasificador, podemos reutilizarlo para procesar otros conjuntos de datos. Es poco común clasificar datos de prueba y validación, ya que estos deberían usarse solo para hacer el clasificador. Aquí aplicamos el clasificador a los puntos de datos restantes, que no han sido anotados.
remaining_data = data[20:]
prediction = classifier.predict(remaining_data)
prediction
array([1, 1, 1, 1, 2, 1, 2, 1, 2, 1, 2, 2, 1, 2, 2, 1, 1, 2, 1, 1, 1, 1,
2, 1, 2, 2, 2, 2, 2, 1, 1, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 1, 2,
2, 2, 1, 1, 1, 1, 1, 2, 1, 1, 2, 2, 2, 1, 1, 2, 2, 1, 2, 2, 2, 1,
1, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 2, 1, 2, 1, 1, 2, 1, 1, 1, 1, 2,
1, 2, 1, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 1, 1, 1, 2, 2, 2,
1, 2, 2, 2, 1, 2, 1, 2, 2, 1, 2, 2, 1, 1, 2, 1, 1, 2, 1, 2, 1, 1,
1, 1, 1, 1, 2, 1, 1, 1, 1, 2, 1, 1, 1, 2, 2, 1, 1, 1, 1, 2, 2, 1,
1, 1, 1, 2, 2, 1, 2, 1, 1, 2, 2, 1, 1, 2, 1, 2, 1, 2, 1, 2, 2, 2,
1, 2, 1, 2, 1, 1, 2, 2, 2, 1, 1, 1, 2, 2, 1, 2, 1, 2, 1, 2, 1, 1,
2, 1, 1, 2, 1, 1, 2, 2, 2, 1, 1, 1, 2, 2, 2, 2, 2, 1, 2, 1, 1, 2,
2, 2, 1, 1, 2, 1, 1, 2, 1, 1, 2, 2, 1, 1, 2, 2, 1, 1, 1, 2, 2, 1,
1, 1, 1, 1, 2, 2, 1, 1, 1, 1, 1, 1, 2, 2, 2, 1, 1, 2, 2, 2, 1, 2,
1, 2, 2, 1, 2, 2, 1, 2, 2, 1, 1, 2, 1, 1, 2, 2])
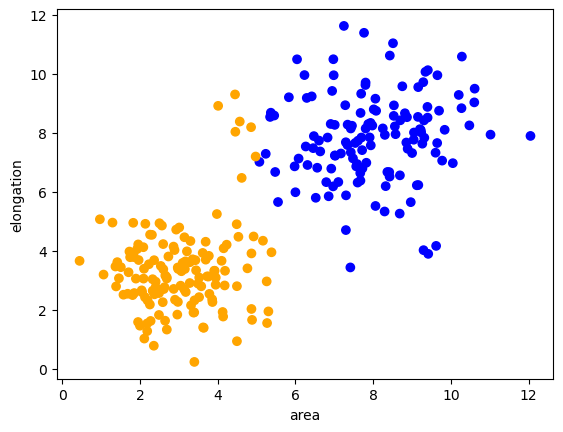
Aquí ahora visualizamos todo el conjunto de datos con colores de clase.
predicted_colors = [colors[i-1] for i in prediction]
plt.scatter(remaining_data[:, 0], remaining_data[:, 1], c=predicted_colors)
plt.xlabel('area')
plt.ylabel('elongation')
Text(0, 0.5, 'elongation')
Ejercicio#
Entrena una Máquina de Vectores de Soporte y visualiza su predicción.
from sklearn.svm import SVC
classifier = SVC()