Estadísticas de toma de decisiones del bosque aleatorio#
Después de entrenar un clasificador de bosque aleatorio, podemos estudiar sus mecanismos internos. APOC permite recuperar el número de decisiones en el bosque basadas en las características dadas.
Ver también
from skimage.io import imread, imsave
import pyclesperanto_prototype as cle
import pandas as pd
import numpy as np
import apoc
import matplotlib.pyplot as plt
import pandas as pd
cle.select_device('RTX')
<NVIDIA GeForce RTX 3050 Ti Laptop GPU on Platform: NVIDIA CUDA (1 refs)>
Con fines de demostración, utilizamos una imagen de David Legland compartida bajo CC-BY 4.0 disponible en el repositorio mathematical_morphology_with_MorphoLibJ.
También añadimos una imagen de etiquetas que se generó en un capítulo anterior.
image = cle.push(imread('../../data/maize_clsm.tif'))
labels = cle.push(imread('../../data/maize_clsm_labels.tif'))
fix, axs = plt.subplots(1,2, figsize=(10,10))
cle.imshow(image, plot=axs[0])
cle.imshow(labels, plot=axs[1], labels=True)

Anteriormente creamos un clasificador de objetos y ahora lo aplicamos al par de imágenes de intensidad y etiquetas.
classifier = apoc.ObjectClassifier("../../data/maize_cslm_object_classifier.cl")
classification_map = classifier.predict(labels=labels, image=image)
cle.imshow(classification_map, labels=True, min_display_intensity=0)
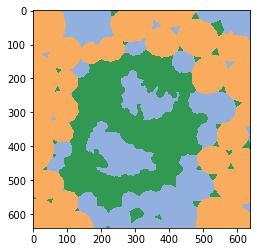
Estadísticas del clasificador#
El clasificador cargado puede proporcionarnos información estadística sobre su estructura interna. El clasificador de bosque aleatorio consiste en muchos árboles de decisión y cada árbol de decisión consiste en decisiones binarias en múltiples niveles. Por ejemplo, un bosque con 10 árboles toma 10 decisiones en el primer nivel, ya que cada árbol toma al menos esta decisión. En el segundo nivel, cada árbol puede tomar hasta 2 decisiones, lo que resulta en un máximo de 20 decisiones en este nivel. Ahora podemos visualizar cuántas decisiones en cada nivel tienen en cuenta características específicas. Las estadísticas se proporcionan como dos diccionarios que pueden visualizarse usando pandas
shares, counts = classifier.statistics()
Primero, mostramos el número de decisiones en cada nivel. De nuevo, de los niveles más bajos a los más altos, el número total de decisiones aumenta, en esta tabla de izquierda a derecha.
pd.DataFrame(counts).T
| 0 | 1 | |
|---|---|---|
| area | 4 | 33 |
| mean_intensity | 32 | 44 |
| standard_deviation_intensity | 37 | 44 |
| touching_neighbor_count | 8 | 28 |
| average_distance_of_n_nearest_neighbors=6 | 19 | 34 |
La tabla anterior nos dice que en el primer nivel, 26 árboles tuvieron en cuenta mean_intensity, que es el número más alto en este nivel. En el segundo nivel, se tomaron 30 decisiones teniendo en cuenta la standard_deviation_intensity. La distancia promedio de los n vecinos más cercanos se tuvo en cuenta 21-29 veces en este nivel, lo cual es cercano. Se podría argumentar que la intensidad y las distancias centroides entre vecinos fueron los parámetros cruciales para diferenciar objetos.
A continuación, observamos las shares normalizadas, que son los conteos divididos por el número total de decisiones tomadas por nivel de profundidad. Visualizamos esto en color para resaltar las características con valores altos y bajos.
def colorize(styler):
styler.background_gradient(axis=None, cmap="rainbow")
return styler
df = pd.DataFrame(shares).T
df.style.pipe(colorize)
| 0 | 1 | |
|---|---|---|
| area | 0.040000 | 0.180328 |
| mean_intensity | 0.320000 | 0.240437 |
| standard_deviation_intensity | 0.370000 | 0.240437 |
| touching_neighbor_count | 0.080000 | 0.153005 |
| average_distance_of_n_nearest_neighbors=6 | 0.190000 | 0.185792 |
Sumando a nuestras ideas descritas anteriormente, también podemos ver aquí que la distribución de las decisiones en los niveles se vuelve más uniforme cuanto más alto es el nivel. Por lo tanto, se podría considerar entrenar un clasificador con tal vez solo dos niveles de profundidad.
Importancia de las características#
Un concepto más común para estudiar la relevancia de las características extraídas es la importancia de las características, que se calcula a partir de las estadísticas del clasificador mostradas anteriormente y puede ser más fácil de interpretar ya que es un solo número que describe cada característica.
feature_importance = classifier.feature_importances()
feature_importance = {k:[v] for k, v in feature_importance.items()}
feature_importance
{'area': [0.1023460967511782],
'mean_intensity': [0.27884719464885743],
'standard_deviation_intensity': [0.34910187501327306],
'touching_neighbor_count': [0.09231893555382481],
'average_distance_of_n_nearest_neighbors=6': [0.1773858980328665]}
def colorize(styler):
styler.background_gradient(axis=None, cmap="rainbow")
return styler
df = pd.DataFrame(feature_importance).T
df.style.pipe(colorize)
| 0 | |
|---|---|
| area | 0.102346 |
| mean_intensity | 0.278847 |
| standard_deviation_intensity | 0.349102 |
| touching_neighbor_count | 0.092319 |
| average_distance_of_n_nearest_neighbors=6 | 0.177386 |