Tracer des distributions avec Seaborn#
Avec Seaborn, il est également très pratique de tracer des distributions de données telles que des boîtes à moustaches, des graphiques en barres, des histogrammes et des tracés d’estimation de densité par noyau.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
Nous commençons par charger un tableau de mesures dans un DataFrame pandas.
df = pd.read_csv("../../data/BBBC007_analysis.csv")
df
| area | intensity_mean | major_axis_length | minor_axis_length | aspect_ratio | file_name | |
|---|---|---|---|---|---|---|
| 0 | 139 | 96.546763 | 17.504104 | 10.292770 | 1.700621 | 20P1_POS0010_D_1UL |
| 1 | 360 | 86.613889 | 35.746808 | 14.983124 | 2.385805 | 20P1_POS0010_D_1UL |
| 2 | 43 | 91.488372 | 12.967884 | 4.351573 | 2.980045 | 20P1_POS0010_D_1UL |
| 3 | 140 | 73.742857 | 18.940508 | 10.314404 | 1.836316 | 20P1_POS0010_D_1UL |
| 4 | 144 | 89.375000 | 13.639308 | 13.458532 | 1.013432 | 20P1_POS0010_D_1UL |
| ... | ... | ... | ... | ... | ... | ... |
| 106 | 305 | 88.252459 | 20.226532 | 19.244210 | 1.051045 | 20P1_POS0007_D_1UL |
| 107 | 593 | 89.905565 | 36.508370 | 21.365394 | 1.708762 | 20P1_POS0007_D_1UL |
| 108 | 289 | 106.851211 | 20.427809 | 18.221452 | 1.121086 | 20P1_POS0007_D_1UL |
| 109 | 277 | 100.664260 | 20.307965 | 17.432920 | 1.164920 | 20P1_POS0007_D_1UL |
| 110 | 46 | 70.869565 | 11.648895 | 5.298003 | 2.198733 | 20P1_POS0007_D_1UL |
111 rows × 6 columns
Boîtes à moustaches#
La fonction axes pour tracer des boîtes à moustaches est boxplot.
Seaborn a déjà identifié file_name comme une valeur catégorielle et intensity_mean comme une valeur numérique. Ainsi, il trace des boîtes à moustaches pour la variable d’intensité. Si nous inversons x et y, nous obtenons toujours le même graphique, mais sous forme de boîtes à moustaches verticales.
sns.boxplot(data=df, x="intensity_mean", y="file_name")
<AxesSubplot: xlabel='intensity_mean', ylabel='file_name'>
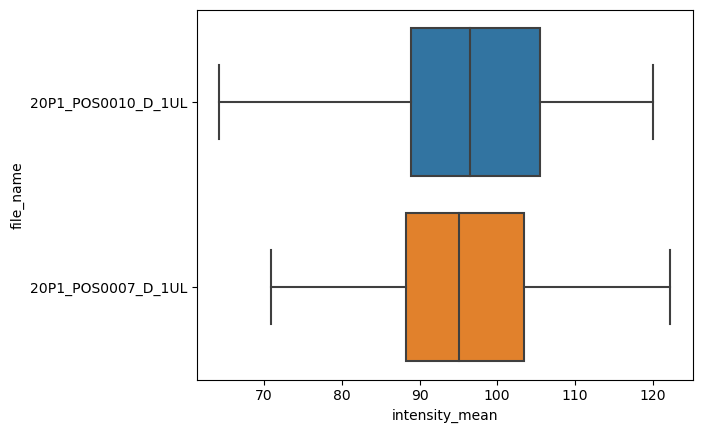
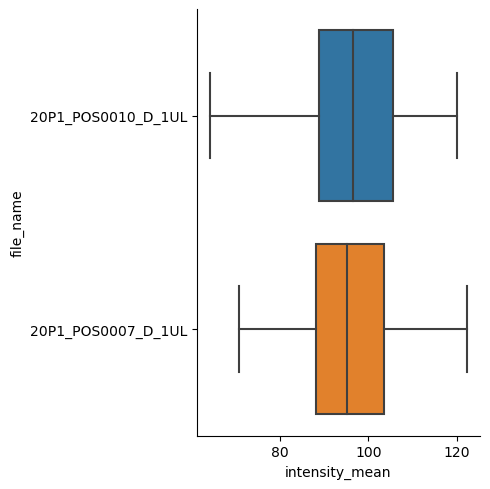
La version au niveau de la figure, et plus générale, de ce type de tracé est catplot. Nous devons simplement fournir kind comme box.
sns.catplot(data=df, x="intensity_mean", y="file_name", kind="box")
<seaborn.axisgrid.FacetGrid at 0x27775d754f0>
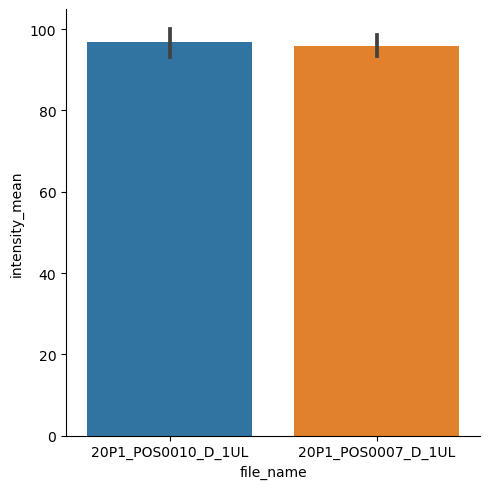
Il existe d’autres types disponibles, comme un graphique en bar.
sns.catplot(data=df, x="file_name", y="intensity_mean", kind="bar")
<seaborn.axisgrid.FacetGrid at 0x2777b1abb80>
Histogrammes et tracés de distribution#
La fonction au niveau des axes pour tracer des histogrammes est histplot.
sns.histplot(data = df, x="intensity_mean", hue="file_name")
<AxesSubplot: xlabel='intensity_mean', ylabel='Count'>
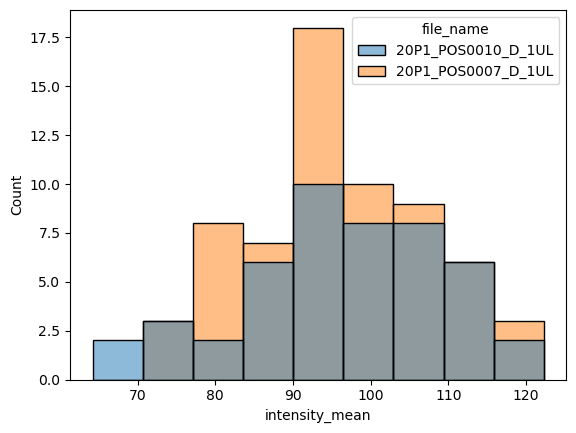
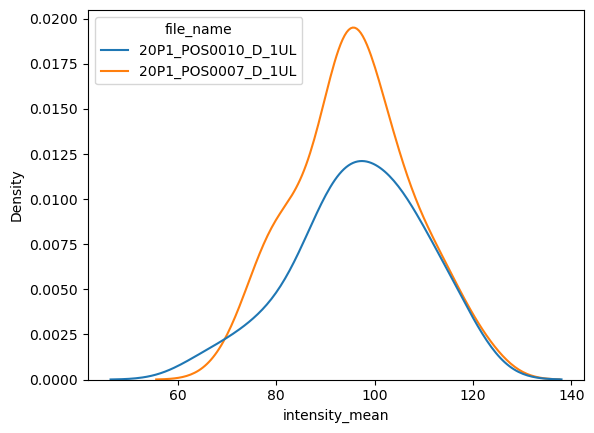
Nous pouvons plutôt tracer l’estimation de densité par noyau (kde) avec la fonction kdeplot. Soyez juste prudent lors de l’interprétation de ces tracés (vérifiez quelques pièges ici)
sns.kdeplot(data=df, x="intensity_mean", hue="file_name")
<AxesSubplot: xlabel='intensity_mean', ylabel='Density'>
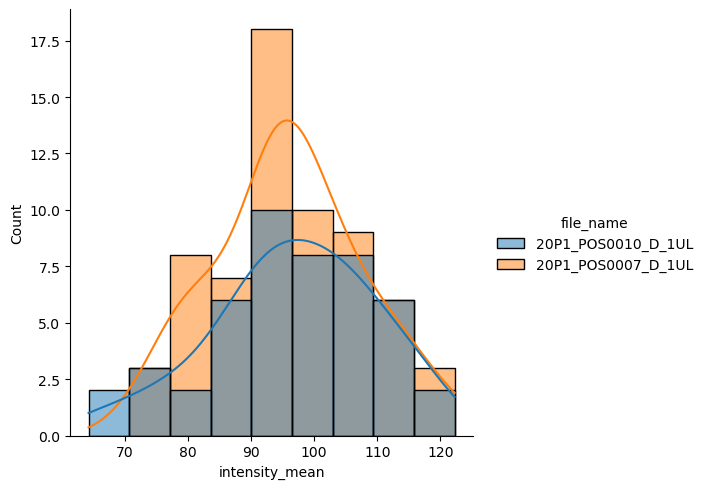
La fonction au niveau de la figure pour les distributions est distplot. Avec elle, vous pouvez avoir des histogrammes et des kde sur le même tracé, ou d’autres types de tracés, comme la fonction de répartition empirique (ecdf).
sns.displot(data = df, x="intensity_mean", hue="file_name", kde=True)
<seaborn.axisgrid.FacetGrid at 0x2777b77c910>
Exercice#
Tracez deux fonctions de répartition empiriques pour ‘area’ à partir de différents fichiers sur un même graphique avec différentes couleurs.
Répétez cela pour la propriété ‘intensity_mean’ sur une seconde figure. Déduisez si vous vous attendriez à ce que ces propriétés soient différentes ou non.
*Astuce : cherchez le paramètre kind de displot