Bande-annonce : Analyse d’images biologiques avec Python#
Dans les chapitres suivants, nous plongerons dans l’analyse d’images, l’apprentissage automatique et les biostatistiques en utilisant Python. Ce premier notebook sert de bande-annonce de ce que nous allons faire.
Les notebooks Python commencent généralement par l’importation des bibliothèques Python que le notebook utilisera. Le lecteur peut d’abord vérifier si toutes ces bibliothèques sont installées avant de parcourir l’ensemble du notebook.
import numpy as np
from skimage.io import imread, imshow
import pyclesperanto_prototype as cle
from skimage import measure
import pandas as pd
import seaborn
import apoc
import stackview
Travailler avec des données d’image#
Nous commençons par charger les données d’image qui nous intéressent. Dans cet exemple, nous chargeons une image montrant un œil de poisson zèbre, gracieuseté de Mauricio Rocha Martins, laboratoire Norden, MPI CBG Dresde.
# open an image file
multichannel_image = imread("../../data/zfish_eye.tif")
# extract a channel
single_channel_image = multichannel_image[:,:,0]
cropped_image = single_channel_image[200:600, 500:900]
stackview.insight(cropped_image)

|

|
Filtrage d’image#
Une étape courante lorsqu’on travaille avec des images de microscopie à fluorescence est la soustraction de l’intensité de fond, par exemple résultant de la lumière hors focus. Cela peut améliorer les résultats de segmentation d’image plus loin dans le flux de travail.
# subtract background using a top-hat filter
background_subtracted_image = cle.top_hat_box(cropped_image, radius_x=20, radius_y=20)
stackview.insight(background_subtracted_image)

|

|
Segmentation d’image#
Pour segmenter les noyaux dans l’image donnée, il existe un grand nombre d’algorithmes. Ici, nous utilisons une approche classique appelée l’étiquetage de Voronoi-Otsu, qui n’est certainement pas parfaite.
label_image = np.asarray(cle.voronoi_otsu_labeling(background_subtracted_image, spot_sigma=4))
# show result
stackview.insight(label_image)

|
|
Mesures et extraction de caractéristiques#
Après que l’image est segmentée, nous pouvons mesurer les propriétés des objets individuels. Ces propriétés sont généralement des paramètres statistiques descriptifs, appelés caractéristiques. Lorsque nous dérivons des mesures telles que la surface ou l’intensité moyenne, nous extrayons ces deux caractéristiques.
statistics = measure.regionprops_table(label_image,
intensity_image=cropped_image,
properties=('area', 'mean_intensity', 'major_axis_length', 'minor_axis_length'))
Travailler avec des tableaux#
L’objet statistics créé ci-dessus contient une structure de données Python, un dictionnaire de vecteurs de mesure, qui n’est pas le plus intuitif à regarder. Par conséquent, nous le convertissons en tableau. Les scientifiques des données appellent souvent ces tableaux des DataFrames, qui sont disponibles dans la bibliothèque pandas.
dataframe = pd.DataFrame(statistics)
Nous pouvons utiliser les colonnes de tableau existantes pour calculer d’autres mesures, comme le aspect_ratio.
dataframe['aspect_ratio'] = dataframe['major_axis_length'] / dataframe['minor_axis_length']
dataframe
| area | mean_intensity | major_axis_length | minor_axis_length | aspect_ratio | |
|---|---|---|---|---|---|
| 0 | 294.0 | 36604.625850 | 25.656180 | 18.800641 | 1.364644 |
| 1 | 91.0 | 37379.769231 | 20.821990 | 6.053507 | 3.439658 |
| 2 | 246.0 | 44895.308943 | 21.830827 | 14.916032 | 1.463581 |
| 3 | 574.0 | 44394.637631 | 37.788705 | 19.624761 | 1.925563 |
| 4 | 518.0 | 45408.903475 | 26.917447 | 24.872908 | 1.082199 |
| ... | ... | ... | ... | ... | ... |
| 108 | 568.0 | 48606.121479 | 37.357606 | 19.808121 | 1.885974 |
| 109 | 175.0 | 25552.074286 | 17.419031 | 13.675910 | 1.273702 |
| 110 | 460.0 | 39031.419565 | 26.138592 | 23.522578 | 1.111213 |
| 111 | 407.0 | 39343.292383 | 28.544027 | 19.563792 | 1.459023 |
| 112 | 31.0 | 29131.322581 | 6.892028 | 5.711085 | 1.206781 |
113 rows × 5 columns
Traçage#
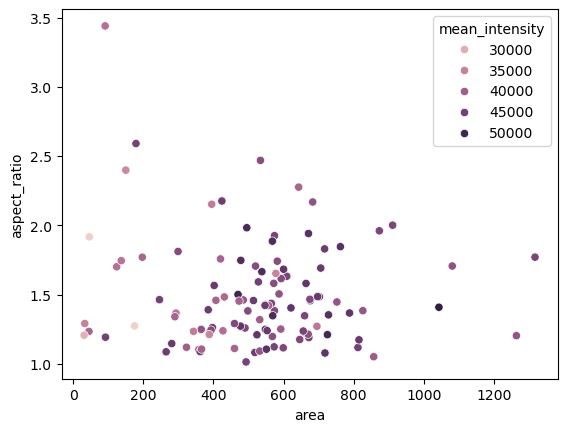
Les mesures peuvent être visualisées à l’aide de graphiques.
seaborn.scatterplot(dataframe, x='area', y='aspect_ratio', hue='mean_intensity')
<Axes: xlabel='area', ylabel='aspect_ratio'>
Statistiques descriptives#
En prenant ce tableau comme point de départ, nous pouvons utiliser des statistiques pour obtenir une vue d’ensemble des données mesurées.
mean_area = np.mean(dataframe['area'])
stddev_area = np.std(dataframe['area'])
print("La surface moyenne du noyau est", mean_area, "+-", stddev_area, "pixels")
Mean nucleus area is 524.4247787610619 +- 231.74703195433014 pixels
Classification#
Pour mieux comprendre la structure interne des tissus, mais aussi pour corriger les artefacts dans les flux de travail de traitement d’image, nous pouvons classer les cellules, par exemple selon leur taille et leur forme.
object_classifier = apoc.ObjectClassifier('../../data/blobs_classifier.cl')
classification_image = object_classifier.predict(label_image, cropped_image)
stackview.imshow(classification_image)
