Comparaison des méthodes#
Supposons que pour un type spécifique de mesure, il existe deux méthodes pour l’effectuer. Une question courante dans ce contexte est de savoir si les deux méthodes pourraient se remplacer mutuellement. Par conséquent, la similitude des mesures est étudiée. Une méthode pour cela est l’analyse de Bland-Altman, nommée d’après Martin Bland et Douglas Altman.
Voir aussi Altman and Bland: Measurement in Medicine: the Analysis of Method Comparison Studies
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
Avant de nous plonger dans l’analyse de Bland-Altman, nous examinons des méthodes directes pour comparer les méthodes. Une hypothèse importante est que nous avons travaillé avec des données appariées. Cela signifie que nous pouvons appliquer les deux méthodes de mesure au même échantillon sans le détruire et sans que les deux méthodes ne se nuisent mutuellement.
# make up some data
measurement_A = [1, 9, 7, 1, 2, 8, 9, 2, 1, 7, 8]
measurement_B = [4, 5, 5, 7, 4, 5, 4, 6, 6, 5, 4]
# show measurements as table
pd.DataFrame([measurement_A, measurement_B], ["A", "B"]).transpose()
| A | B | |
|---|---|---|
| 0 | 1 | 4 |
| 1 | 9 | 5 |
| 2 | 7 | 5 |
| 3 | 1 | 7 |
| 4 | 2 | 4 |
| 5 | 8 | 5 |
| 6 | 9 | 4 |
| 7 | 2 | 6 |
| 8 | 1 | 6 |
| 9 | 7 | 5 |
| 10 | 8 | 4 |
Comparaison des moyennes#
Une méthode très simple pour comparer des tableaux de mesures est de comparer leurs moyennes.
print("Mean(A) = " + str(np.mean(measurement_A)))
print("Mean(B) = " + str(np.mean(measurement_B)))
Mean(A) = 5.0
Mean(B) = 5.0
En utilisant cette méthode, on pourrait conclure que les deux méthodes donnent des mesures similaires car leur moyenne est égale. Cependant, cela pourrait être trompeur.
Graphiques de dispersion#
Une méthode plus visuelle pour comparer les méthodes consiste à dessiner des graphiques de dispersion. Dans ces graphiques, les mesures d’une méthode sont tracées par rapport à l’autre méthode.
plt.plot(measurement_A, measurement_B, "*")
plt.plot([0, 10], [0, 10])
plt.axis([0, 10, 0, 10])
plt.xlabel('measurement A')
plt.ylabel('measurement B')
plt.show()
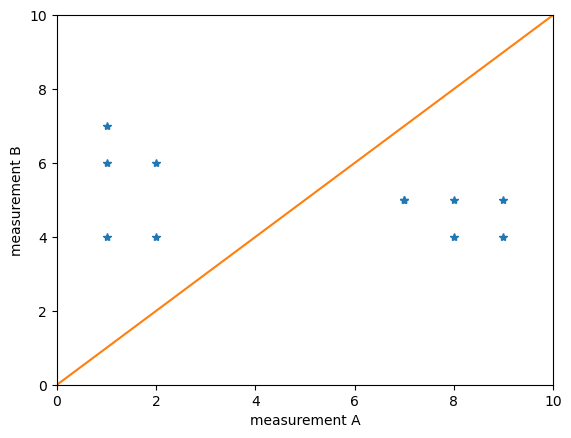
Manifestement, A et B conduisent à des résultats assez différents. Si les points bleus se trouvaient sur la ligne orange, nous conclurions que les mesures sont liées.
Histogrammes#
Comme nous avons déjà conclu que les deux mesures se situent dans des plages différentes, nous devrions examiner la distribution. Les histogrammes sont un bon choix de graphique. Pour s’assurer que les histogrammes des deux mesures sont visualisés de la même manière, par exemple avec la même plage sur l’axe des x, nous pouvons écrire notre propre petite fonction draw_histogram :
def draw_histogram(data):
counts, bins = np.histogram(data, bins=10, range=(0,10))
plt.hist(bins[:-1], bins, weights=counts)
plt.axis([0, 10, 0, 4])
plt.show()
draw_histogram(measurement_A)
draw_histogram(measurement_B)
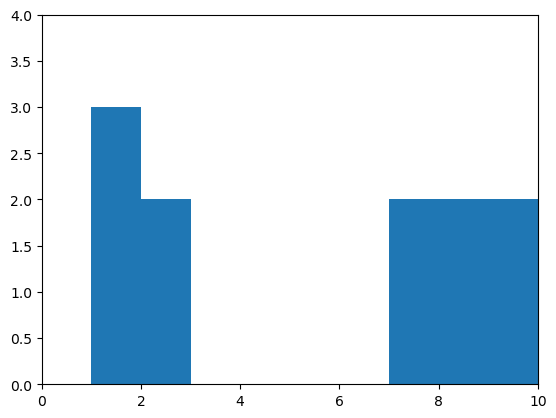
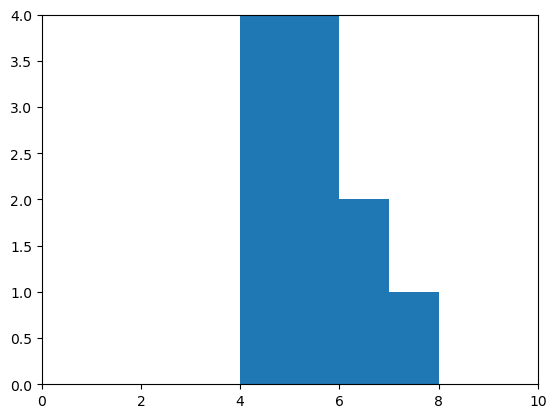
Corrélation#
Pour mesurer la relation entre deux mesures, nous pouvons utiliser la définition de Pearson d’un coefficient de corrélation
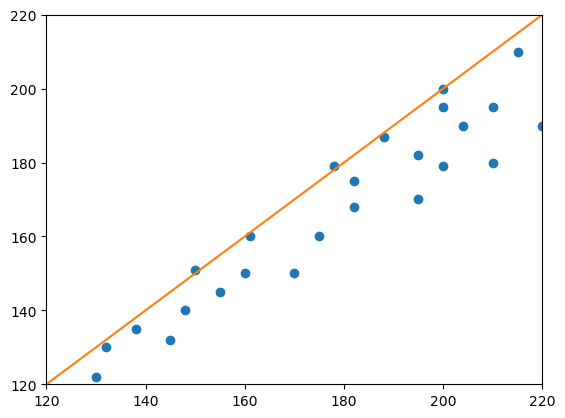
Les données pour l’expérience suivante sont tirées de Altman & Bland, The Statistician 32, 1983, Fig. 1.
# new measurements
measurement_1 = [130, 132, 138, 145, 148, 150, 155, 160, 161, 170, 175, 178, 182, 182, 188, 195, 195, 200, 200, 204, 210, 210, 215, 220, 200]
measurement_2 = [122, 130, 135, 132, 140, 151, 145, 150, 160, 150, 160, 179, 168, 175, 187, 170, 182, 179, 195, 190, 180, 195, 210, 190, 200]
# scatter plot
plt.plot(measurement_1, measurement_2, "o")
plt.plot([120, 220], [120, 220])
plt.axis([120, 220, 120, 220])
plt.show()
# Determining Pearson's correlation coefficient r with a for-loop
import numpy as np
# get the mean of the measurements
mean_1 = np.mean(measurement_1)
mean_2 = np.mean(measurement_2)
# get the number of measurements
n = len(measurement_1)
# get the standard deviation of the measurements
std_dev_1 = np.std(measurement_1)
std_dev_2 = np.std(measurement_2)
# sum the expectation of
sum = 0
for m_1, m_2 in zip(measurement_1, measurement_2):
sum = sum + (m_1 - mean_1) * (m_2 - mean_2) / n
r = sum / (std_dev_1 * std_dev_2)
print ("r = " + str(r))
r = 0.9435300113035253
# Determine Pearson's r using scipy
from scipy import stats
stats.pearsonr(measurement_1, measurement_2)[0]
0.9435300113035257
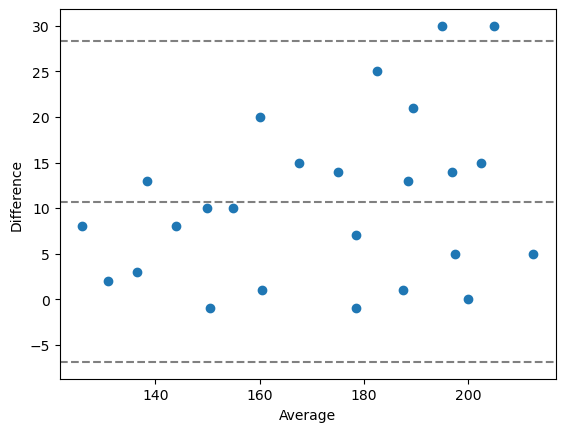
Graphiques de Bland-Altman#
Les graphiques de Bland-Altman sont une façon de visualiser spécifiquement les différences entre les mesures appariées. Lorsqu’on recherche sur Google du code Python qui dessine de tels graphiques, on peut aboutir à cette solution :
# A function for drawing Bland-Altman plots
# source https://stackoverflow.com/questions/16399279/bland-altman-plot-in-python
import matplotlib.pyplot as plt
import numpy as np
def bland_altman_plot(data1, data2, *args, **kwargs):
data1 = np.asarray(data1)
data2 = np.asarray(data2)
mean = np.mean([data1, data2], axis=0)
diff = data1 - data2 # Difference between data1 and data2
md = np.mean(diff) # Mean of the difference
sd = np.std(diff, axis=0) # Standard deviation of the difference
plt.scatter(mean, diff, *args, **kwargs)
plt.axhline(md, color='gray', linestyle='--')
plt.axhline(md + 1.96*sd, color='gray', linestyle='--')
plt.axhline(md - 1.96*sd, color='gray', linestyle='--')
plt.xlabel("Average")
plt.ylabel("Difference")
# draw a Bland-Altman plot
bland_altman_plot(measurement_1, measurement_2)
plt.show()
Exercice#
Traitez à nouveau l’ensemble de données de bananes, par exemple en utilisant une boucle for qui parcourt le dossier ../data/banana/, et traite toutes les images. Mesurez la taille des tranches de banane en utilisant les méthodes de seuillage de scikit-image threshold_otsu et threshold_yen. Comparez les deux méthodes en utilisant les techniques que vous avez apprises ci-dessus.