Statistiques de prise de décision de la forêt aléatoire#
Après avoir entraîné un classifieur de forêt aléatoire, nous pouvons étudier ses mécanismes internes. APOC permet de récupérer le nombre de décisions dans la forêt basées sur les caractéristiques données.
Voir aussi
from skimage.io import imread, imsave
import pyclesperanto_prototype as cle
import pandas as pd
import numpy as np
import apoc
import matplotlib.pyplot as plt
import pandas as pd
cle.select_device('RTX')
<NVIDIA GeForce RTX 3050 Ti Laptop GPU on Platform: NVIDIA CUDA (1 refs)>
À des fins de démonstration, nous utilisons une image de David Legland partagée sous CC-BY 4.0 disponible dans le dépôt mathematical_morphology_with_MorphoLibJ.
Nous ajoutons également une image d’étiquettes qui a été générée dans un chapitre précédent.
image = cle.push(imread('../../data/maize_clsm.tif'))
labels = cle.push(imread('../../data/maize_clsm_labels.tif'))
fix, axs = plt.subplots(1,2, figsize=(10,10))
cle.imshow(image, plot=axs[0])
cle.imshow(labels, plot=axs[1], labels=True)

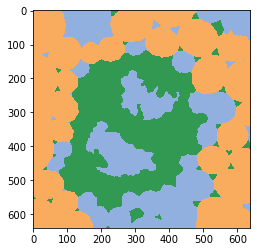
Nous avons précédemment créé un classifieur d’objets et l’appliquons maintenant à la paire d’images d’intensité et d’étiquettes.
classifier = apoc.ObjectClassifier("../../data/maize_cslm_object_classifier.cl")
classification_map = classifier.predict(labels=labels, image=image)
cle.imshow(classification_map, labels=True, min_display_intensity=0)
Statistiques du classifieur#
Le classifieur chargé peut nous fournir des informations statistiques sur sa structure interne. Le classifieur de forêt aléatoire se compose de nombreux arbres de décision et chaque arbre de décision se compose de décisions binaires à plusieurs niveaux. Par exemple, une forêt de 10 arbres prend 10 décisions au premier niveau, car chaque arbre prend au moins cette décision. Au deuxième niveau, chaque arbre peut prendre jusqu’à 2 décisions, ce qui donne un maximum de 20 décisions à ce niveau. Nous pouvons maintenant visualiser combien de décisions à chaque niveau prennent en compte des caractéristiques spécifiques. Les statistiques sont données sous forme de deux dictionnaires qui peuvent être visualisés à l’aide de pandas
shares, counts = classifier.statistics()
Tout d’abord, nous affichons le nombre de décisions à chaque niveau. Encore une fois, des niveaux inférieurs aux niveaux supérieurs, le nombre total de décisions augmente, dans ce tableau de gauche à droite.
pd.DataFrame(counts).T
| 0 | 1 | |
|---|---|---|
| area | 4 | 33 |
| mean_intensity | 32 | 44 |
| standard_deviation_intensity | 37 | 44 |
| touching_neighbor_count | 8 | 28 |
| average_distance_of_n_nearest_neighbors=6 | 19 | 34 |
Le tableau ci-dessus nous indique qu’au premier niveau, 26 arbres ont pris en compte mean_intensity, ce qui est le nombre le plus élevé à ce niveau. Au deuxième niveau, 30 décisions ont été prises en tenant compte de standard_deviation_intensity. La distance moyenne des n voisins les plus proches a été prise en compte 21-29 fois à ce niveau, ce qui est proche. On pourrait dire que l’intensité et les distances centroïdes entre voisins étaient les paramètres cruciaux pour différencier les objets.
Ensuite, nous examinons les shares normalisées, qui sont les comptages divisés par le nombre total de décisions prises par niveau de profondeur. Nous visualisons cela en couleur pour mettre en évidence les caractéristiques avec des valeurs élevées et basses.
def colorize(styler):
styler.background_gradient(axis=None, cmap="rainbow")
return styler
df = pd.DataFrame(shares).T
df.style.pipe(colorize)
| 0 | 1 | |
|---|---|---|
| area | 0.040000 | 0.180328 |
| mean_intensity | 0.320000 | 0.240437 |
| standard_deviation_intensity | 0.370000 | 0.240437 |
| touching_neighbor_count | 0.080000 | 0.153005 |
| average_distance_of_n_nearest_neighbors=6 | 0.190000 | 0.185792 |
En complément de nos observations décrites ci-dessus, nous pouvons également voir ici que la distribution des décisions sur les niveaux devient plus uniforme plus le niveau est élevé. Par conséquent, on pourrait envisager d’entraîner un classifieur avec peut-être seulement deux niveaux de profondeur.
Importance des caractéristiques#
Un concept plus courant pour étudier la pertinence des caractéristiques extraites est l’importance des caractéristiques, qui est calculée à partir des statistiques du classifieur montrées ci-dessus et peut être plus facile à interpréter car c’est un seul nombre décrivant chaque caractéristique.
feature_importance = classifier.feature_importances()
feature_importance = {k:[v] for k, v in feature_importance.items()}
feature_importance
{'area': [0.1023460967511782],
'mean_intensity': [0.27884719464885743],
'standard_deviation_intensity': [0.34910187501327306],
'touching_neighbor_count': [0.09231893555382481],
'average_distance_of_n_nearest_neighbors=6': [0.1773858980328665]}
def colorize(styler):
styler.background_gradient(axis=None, cmap="rainbow")
return styler
df = pd.DataFrame(feature_importance).T
df.style.pipe(colorize)
| 0 | |
|---|---|
| area | 0.102346 |
| mean_intensity | 0.278847 |
| standard_deviation_intensity | 0.349102 |
| touching_neighbor_count | 0.092319 |
| average_distance_of_n_nearest_neighbors=6 | 0.177386 |