Parallélisation avec numba#
Dans ce notebook, nous allons optimiser le temps d’exécution d’un algorithme en utilisant numba.
import time
import numpy as np
from functools import partial
import timeit
import matplotlib.pyplot as plt
import platform
image = np.zeros((10, 10))
Évaluation du temps d’exécution#
Dans le traitement d’image, il est très courant que le temps d’exécution des algorithmes présente des modèles différents selon la taille de l’image. Nous allons maintenant évaluer l’algorithme ci-dessus et voir comment il se comporte sur des images de différentes tailles. Pour lier une fonction à évaluer à une image donnée sans l’exécuter, nous utilisons le modèle partial.
def benchmark(target_function):
"""
Tests a function on a couple of image sizes and returns times taken for processing.
"""
sizes = np.arange(1, 5) * 10
benchmark_data = []
for size in sizes:
print("Size", size)
# make new data
image = np.zeros((size, size))
# bind target function to given image
partial_function = partial(target_function, image)
# measure execution time
time_in_s = timeit.timeit(partial_function, number=10)
print("time", time_in_s, "s")
# store results
benchmark_data.append([size, time_in_s])
return np.asarray(benchmark_data)
Voici l’algorithme que nous aimerions optimiser :
def silly_sum(image):
# Silly algorithm for wasting compute time
sum = 0
for i in range(image.shape[1]):
for j in range(image.shape[0]):
for k in range(image.shape[0]):
for l in range(image.shape[0]):
sum = sum + image[i,j] - k + l
sum = sum + i
image[i, j] = sum / image.shape[1] / image.shape[0]
benchmark_data_silly_sum = benchmark(silly_sum)
Size 10
time 0.026225900000000024 s
Size 20
time 0.3880397999999996 s
Size 30
time 2.4635917000000003 s
Size 40
time 6.705509999999999 s
plt.scatter(benchmark_data_silly_sum[:,0] ** 2, benchmark_data_silly_sum[:,1])
plt.legend(["normal"])
plt.xlabel("Image size in pixels")
plt.ylabel("Compute time in s")
plt.show()
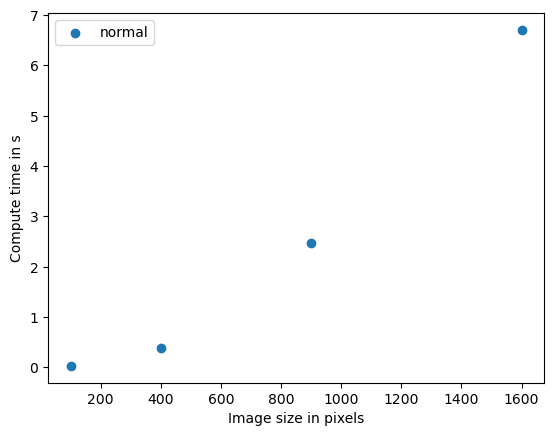
Cet algorithme dépend fortement de la taille de l’image, le graphique montre une complexité approximativement quadratique. Cela signifie que si la taille des données double, le temps de calcul est multiplié par quatre. La notation O de l’algorithme est O(n^2). On pourrait supposer qu’un algorithme similaire appliqué en 3D a une complexité cubique, O(n^3). Si de tels algorithmes constituent des goulots d’étranglement dans votre science, la parallélisation et l’accélération GPU ont beaucoup de sens.
Optimisation du code avec numba#
Dans le cas où le code que nous exécutons est simple et utilise uniquement des fonctions standard python, numpy, etc., nous pouvons utiliser un compilateur juste-à-temps (JIT), par exemple fourni par numba pour accélérer le code.
from numba import jit
@jit
def process_image_compiled(image):
for x in range(image.shape[1]):
for y in range(image.shape[1]):
# Silly algorithm for wasting compute time
sum = 0
for i in range(1000):
for j in range(1000):
sum = sum + x
sum = sum + y
image[x, y] = sum
%timeit process_image_compiled(image)
The slowest run took 56.00 times longer than the fastest. This could mean that an intermediate result is being cached.
2.84 µs ± 5.7 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)