Bases de l’optimisation#
Dans ce notebook, nous démontrons comment configurer un flux de travail de segmentation d’image et optimiser ses paramètres avec une annotation éparse donnée.
Voir aussi :
from skimage.io import imread
from scipy.optimize import minimize
import numpy as np
import pyclesperanto_prototype as cle
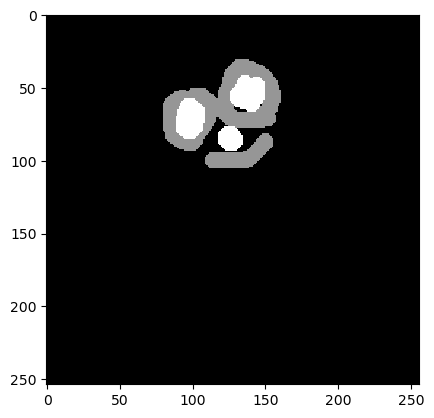
Nous commençons par charger une image d’exemple et une annotation manuelle. Tous les objets ne doivent pas être annotés (annotation éparse).
blobs = imread('../../data/blobs.tif')
cle.imshow(blobs)

annotation = imread('../../data/blobs_annotated.tif')
cle.imshow(annotation)
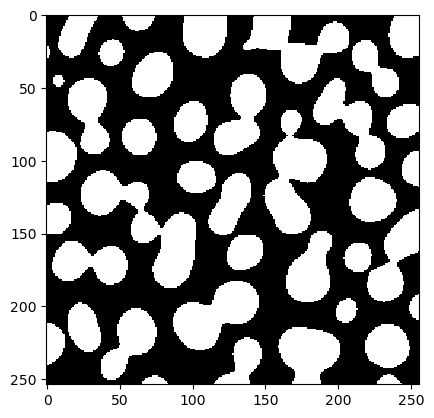
Ensuite, nous définissons un flux de travail de traitement d’image qui aboutit à une image binaire.
def workflow(image, sigma, threshold):
blurred = cle.gaussian_blur(image, sigma_x=sigma, sigma_y=sigma)
binary = cle.greater_constant(blurred, constant=threshold)
return binary
Nous testons également ce flux de travail avec des valeurs aléatoires de sigma et threshold.
test = workflow(blobs, 5, 100)
cle.imshow(test)
Notre fonction d’évaluation prend deux paramètres : Un résultat de segmentation donné (test) et une annotation de référence. Elle détermine ensuite la qualité de la segmentation, par exemple en utilisant l’indice de Jaccard.
binary_and = cle.binary_and
def fitness(test, reference):
"""
Détermine à quel point une segmentation de test donnée est correcte.
Comme métrique, nous utilisons l'indice de Jaccard.
Hypothèse : test est une image binaire (0=Faux et 1=Vrai) et
reference est une image avec 0=inconnu, 1=Faux, 2=Vrai.
"""
negative_reference = reference == 1
positive_reference = reference == 2
negative_test = test == 0
positive_test = test == 1
# vrai positif : test = 1, ref = 2
tp = binary_and(positive_reference, positive_test).sum()
# vrai négatif :
tn = binary_and(negative_reference, negative_test).sum()
# faux positif
fp = binary_and(negative_reference, positive_test).sum()
# faux négatif
fn = binary_and(positive_reference, negative_test).sum()
# retourne l'Indice de Jaccard
return tp / (tp + fn + fp)
fitness(test, annotation)
0.74251497
Nous devrions également tester cette fonction sur une gamme de paramètres.
sigma = 5
for threshold in range(70, 180, 10):
test = workflow(blobs, sigma, threshold)
print(threshold, fitness(test, annotation))
70 0.49048626
80 0.5843038
90 0.67019403
100 0.74251497
110 0.8183873
120 0.8378158
130 0.79089373
140 0.7024014
150 0.60603446
160 0.49827588
170 0.3974138
Ensuite, nous définissons une fonction fun qui ne prend que des paramètres numériques à optimiser.
def fun(x):
# appliquer le réglage actuel des paramètres
test = workflow(blobs, x[0], x[1])
# comme nous minimisons, nous multiplions le fitness par -1
return -fitness(test, annotation)
Avant de commencer l’optimisation, la dernière étape consiste à configurer le point de départ x0 pour l’optimisation et le critère d’arrêt atol, la valeur de tolérance absolue.
# point de départ dans l'espace des paramètres
x0 = np.array([5, 100])
# exécuter l'optimisation
result = minimize(fun, x0, method='nelder-mead', options={'xatol': 1e-3})
result
final_simplex: (array([[ 3.89501953, 121.94091797],
[ 3.89498663, 121.9409585 ],
[ 3.89500463, 121.9403702 ]]), array([-0.85761315, -0.85761315, -0.85761315]))
fun: -0.8576131463050842
message: 'Optimization terminated successfully.'
nfev: 65
nit: 22
status: 0
success: True
x: array([ 3.89501953, 121.94091797])
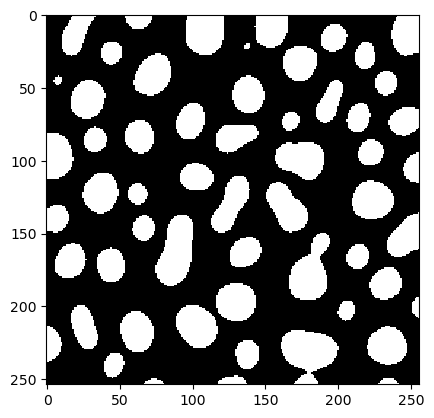
À partir de cet objet result, nous pouvons extraire l’ensemble de paramètres qui a été déterminé comme optimal et produire une image binaire.
x = result['x']
best_binary = workflow(blobs, x[0], x[1])
cle.imshow(best_binary)
Une note sur la convergence#
Les algorithmes d’optimisation ne trouvent pas toujours l’optimum global. La réussite dépend du point de départ de l’optimisation, de la forme de l’espace des paramètres et de l’algorithme choisi. Dans l’exemple suivant, nous montrons à quoi peut ressembler une optimisation échouée si le point de départ a été mal choisi.
# point de départ dans l'espace des paramètres
x0 = np.array([0, 60])
# exécuter l'optimisation
result = minimize(fun, x0, method='nelder-mead', options={'xatol': 1e-3})
result
final_simplex: (array([[0.00000000e+00, 6.00000000e+01],
[6.10351563e-08, 6.00000000e+01],
[0.00000000e+00, 6.00007324e+01]]), array([-0.63195992, -0.63195992, -0.63195992]))
fun: -0.6319599151611328
message: 'Optimization terminated successfully.'
nfev: 51
nit: 13
status: 0
success: True
x: array([ 0., 60.])
Dépannage : Explorer l’espace des paramètres#
Dans ce cas, l’ensemble de paramètres résultant n’est pas différent du point de départ. Si le fitness ne change pas autour du point de départ, l’algorithme d’optimisation ne sait pas comment améliorer le résultat. Visualiser les valeurs autour du point de départ peut aider.
sigma = 0
for threshold in range(57, 63):
test = workflow(blobs, sigma, threshold)
print(threshold, fitness(test, annotation))
57 0.6319599
58 0.6319599
59 0.6319599
60 0.6319599
61 0.6319599
62 0.6319599
threshold = 60
for sigma in np.arange(0, 0.5, 0.1):
test = workflow(blobs, sigma, threshold)
print(sigma, fitness(test, annotation))
0.0 0.6319599
0.1 0.6319599
0.2 0.6319599
0.30000000000000004 0.6319599
0.4 0.6319599
Ainsi, une certaine exploration manuelle de l’espace des paramètres avant d’exécuter l’optimisation automatique a du sens.