Parallélisation#
Lors de la programmation d’algorithmes personnalisés en python, il peut arriver que notre code devienne lent car nous exécutons quelques boucles for imbriquées. Si les boucles internes ne dépendent pas les unes des autres, le code peut être parallélisé et accéléré. Notez que nous parallélisons le code sur une unité centrale de traitement (CPU) et ne le confondez pas avec l’accélération GPU qui utilise des unités de traitement graphique (GPU).
Voir aussi
import time
import numpy as np
from functools import partial
import timeit
import matplotlib.pyplot as plt
import platform
Nous commençons par un algorithme qui fait quelque chose avec une image à des coordonnées de pixels données
def slow_thing(image, x, y):
# Silly algorithm for wasting compute time
sum = 0
for i in range(1000):
for j in range(100):
sum = sum + x
sum = sum + y
image[x, y] = sum
image = np.zeros((10, 10))
Nous utilisons maintenant timeit pour mesurer combien de temps prend l’opération pour traiter un seul pixel.
%timeit slow_thing(image, 4, 5)
3.3 ms ± 395 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Nous définissons maintenant l’opération sur l’ensemble de l’image et mesurons le temps de cette fonction.
def process_image(image):
for x in range(image.shape[1]):
for y in range(image.shape[1]):
slow_thing(image, x, y)
%timeit process_image(image)
353 ms ± 42.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Cette fonction est assez lente et la parallélisation peut avoir du sens.
Parallélisation utilisant joblib.Parallel#
Une approche simple et directe pour la parallélisation consiste à utiliser joblib.Parallel et joblib.delayed.
from joblib import Parallel, delayed, cpu_count
Notez l’écriture inversée des boucles for dans le bloc suivant. Le terme delayed(slow_thing)(image, x, y) est techniquement un appel de fonction qui n’est pas exécuté. Plus tard, lorsque la valeur de retour de cet appel sera réellement nécessaire, l’exécution réelle aura lieu. Voir dask delayed pour plus de détails.
def process_image_parallel(image):
Parallel(n_jobs=-1)(delayed(slow_thing)(image, x, y)
for y in range(image.shape[0])
for x in range(image.shape[1]))
%timeit process_image_parallel(image)
62.4 ms ± 218 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
Une accélération de 7 n’est pas mal. Le n_jobs=-1 implique que toutes les unités de calcul / threads sont utilisées. Nous pouvons également imprimer le nombre de cœurs de calcul utilisés :
cpu_count()
16
À des fins de documentation, nous pouvons également imprimer sur quel type de CPU cet algorithme a été exécuté. Cette chaîne peut être plus ou moins informative selon le système d’exploitation / ordinateur sur lequel nous exécutons ce notebook.
platform.processor()
'AMD64 Family 25 Model 68 Stepping 1, AuthenticAMD'
Benchmarking du temps d’exécution#
En traitement d’image, il est très courant que le temps d’exécution des algorithmes montre des modèles différents selon la taille de l’image. Nous allons maintenant comparer l’algorithme ci-dessus et voir comment il se comporte sur des images de différentes tailles. Pour lier une fonction à comparer à une image donnée sans l’exécuter, nous utilisons le modèle partial.
def benchmark(target_function):
"""
Tests a function on a couple of image sizes and returns times taken for processing.
"""
sizes = np.arange(1, 5) * 10
benchmark_data = []
for size in sizes:
print("Size", size)
# make new data
image = np.zeros((size, size))
# bind target function to given image
partial_function = partial(target_function, image)
# measure execution time
time_in_s = timeit.timeit(partial_function, number=10)
print("time", time_in_s, "s")
# store results
benchmark_data.append([size, time_in_s])
return np.asarray(benchmark_data)
print("Benchmarking normal")
benchmark_data_normal = benchmark(process_image)
print("Benchmarking parallel")
benchmark_data_parallel = benchmark(process_image_parallel)
Benchmarking normal
Size 10
time 3.5427859 s
Size 20
time 13.8465019 s
Size 30
time 30.883478699999998 s
Size 40
time 55.4255712 s
Benchmarking parallel
Size 10
time 0.7873560999999967 s
Size 20
time 2.0985788000000127 s
Size 30
time 4.9782009000000045 s
Size 40
time 7.9171936000000045 s
plt.scatter(benchmark_data_normal[:,0] ** 2, benchmark_data_normal[:,1])
plt.scatter(benchmark_data_parallel[:,0] ** 2, benchmark_data_parallel[:,1])
plt.legend(["normal", "parallel"])
plt.xlabel("Taille de l'image en pixels")
plt.ylabel("Temps de calcul en s")
plt.show()
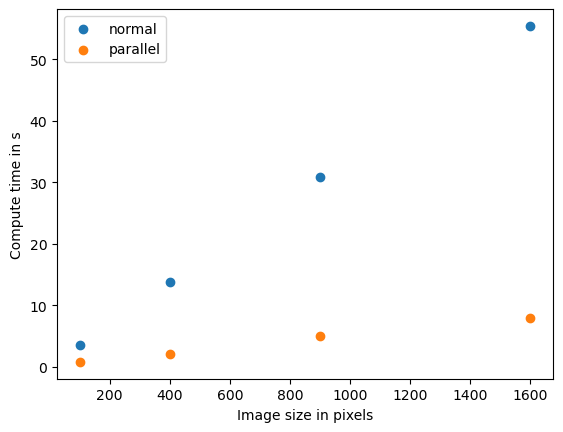
Si nous voyons ce modèle, nous parlons d’une relation linéaire entre la taille des données et le temps de calcul. Les informaticiens utilisent la notation O pour décrire la complexité des algorithmes. Cet algorithme a O(n) et n représente le nombre de pixels dans ce cas.
Assurance qualité#
Notez que dans cette section, nous avons seulement mesuré le temps de calcul des algorithmes. Nous n’avons pas déterminé si les différentes versions optimisées des algorithmes produisent le même résultat. L’assurance qualité est une bonne pratique scientifique. Cela est également pertinent dans le contexte de l’accélération GPU et est par exemple décrit en détail ici.