Traitement d’images en mosaïque, un aperçu rapide#
Dans ce notebook, nous allons traiter un grand jeu de données qui a été sauvegardé au format zarr pour compter les cellules dans des tuiles individuelles en utilisant dask et zarr. Les principes sous-jacents seront expliqués dans les sections suivantes.
import zarr
import dask.array as da
import numpy as np
from skimage.io import imread
import pyclesperanto_prototype as cle
from pyclesperanto_prototype import imshow
from numcodecs import Blosc
À des fins de démonstration, nous utilisons un jeu de données fourni par Theresa Suckert, OncoRay, Hôpital Universitaire Carl Gustav Carus, TU Dresden. Le jeu de données est sous licence Licence : CC-BY 4.0. Nous utilisons ici une version recadrée qui a été ré-enregistrée en image 8 bits pour pouvoir la fournir avec le notebook. Vous trouverez l’image complète en 16 bits au format CZI en ligne. Le contexte biologique est expliqué dans Suckert et al. 2020, où nous avons également appliqué un flux de travail similaire.
Lorsque vous travaillez avec de grandes données, vous aurez probablement une image stockée dans le bon format dès le départ. À des fins de démonstration, nous sauvegardons ici une image test au format zarr, qui est couramment utilisé pour manipuler de grandes données d’images.
# Resave a test image into tiled zarr format
input_filename = '../../data/P1_H_C3H_M004_17-cropped.tif'
zarr_filename = '../../data/P1_H_C3H_M004_17-cropped.zarr'
image = imread(input_filename)[1]
compressor = Blosc(cname='zstd', clevel=3, shuffle=Blosc.BITSHUFFLE)
zarray = zarr.array(image, chunks=(100, 100), compressor=compressor)
zarr.convenience.save(zarr_filename, zarray)
Chargement de l’image sauvegardée en zarr#
Dask offre un support intégré pour le format de fichier zarr. Nous pouvons créer des tableaux dask directement à partir d’un fichier zarr.
zarr_image = da.from_zarr(zarr_filename)
zarr_image
|
Nous pouvons appliquer un traitement d’image directement à ce jeu de données en mosaïque.
Comptage des noyaux#
Pour compter les noyaux, nous mettons en place un simple flux de traitement d’image. Il renvoie une image avec un seul pixel contenant le nombre de noyaux dans l’image d’entrée donnée. Ces pixels uniques seront assemblés pour former une carte de comptage de pixels ; une image avec beaucoup moins de pixels que l’image originale, mais avec l’avantage que nous pouvons la regarder - ce n’est plus une grande donnée.
def count_nuclei(image):
"""
Label objects in a binary image and produce a pixel-count-map image.
"""
# Count nuclei including those which touch the image border
labels = cle.voronoi_otsu_labeling(image, spot_sigma=3.5)
label_intensity_map = cle.mean_intensity_map(image, labels)
high_intensity_labels = cle.exclude_labels_with_map_values_within_range(label_intensity_map, labels, maximum_value_range=20)
nuclei_count = high_intensity_labels.max()
# Count nuclei including those which touch the image border
labels_without_borders = cle.exclude_labels_on_edges(high_intensity_labels)
nuclei_count_excluding_borders = labels_without_borders.max()
# Both nuclei-count including and excluding nuclei at image borders
# are no good approximation. We should exclude the nuclei only on
# half of the borders to get a good estimate.
# Alternatively, we just take the average of both counts.
result = np.asarray([[(nuclei_count + nuclei_count_excluding_borders) / 2]])
return result
Avant de pouvoir commencer le calcul, nous devons désactiver l’exécution asynchrone des opérations dans pyclesperanto. Voir aussi le problème connexe.
cle.set_wait_for_kernel_finish(True)
Pour traiter les tuiles avec dask, nous configurons des blocs de traitement sans chevauchement.
tile_map = da.map_blocks(count_nuclei, zarr_image)
tile_map
|
Comme l’image résultante est beaucoup plus petite que l’originale, nous pouvons calculer toute la carte de résultats.
result = tile_map.compute()
result.shape
(20, 50)
Encore une fois, comme la carte de résultats est petite, nous pouvons simplement la visualiser.
cle.imshow(result, colorbar=True)
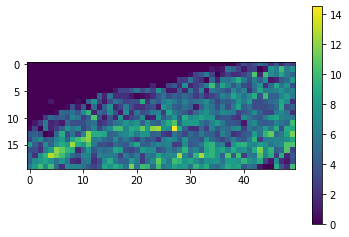
Avec une vérification visuelle rapide dans l’image originale, nous pouvons voir qu’effectivement dans le coin supérieur gauche de l’image, il y a beaucoup moins de cellules que dans le coin inférieur droit.
cle.imshow(cle.voronoi_otsu_labeling(image, spot_sigma=3.5), labels=True)
