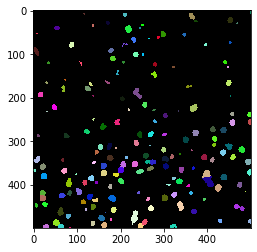Comptage des noyaux dans les tuiles#
Dans ce notebook, nous allons traiter un grand ensemble de données qui a été sauvegardé au format zarr pour compter les cellules dans des tuiles individuelles. Pour chaque tuile, nous écrirons un pixel dans une image de sortie. Ainsi, nous produisons une image de comptage de cellules qui est plus petite que l’image originale d’un facteur correspondant à la taille de la tuile.
import zarr
import dask.array as da
import numpy as np
from skimage.io import imread
import pyclesperanto_prototype as cle
from pyclesperanto_prototype import imshow
from numcodecs import Blosc
À des fins de démonstration, nous utilisons un ensemble de données fourni par Theresa Suckert, OncoRay, Hôpital Universitaire Carl Gustav Carus, TU Dresden. L’ensemble de données est sous licence Licence : CC-BY 4.0. Nous utilisons ici une version recadrée qui a été reenregistrée en tant qu’image 8 bits pour pouvoir la fournir avec le notebook. Vous trouverez l’image 16 bits en taille complète au format de fichier CZI en ligne.
image = imread('../../data/P1_H_C3H_M004_17-cropped.tif')[1]
# pour des besoins de test, nous recadrons encore plus l'image.
# commentez la ligne suivante pour exécuter sur l'ensemble des 5000x2000 pixels
image = image[1000:1500, 1000:1500]
#compresser ET transformer le tableau numpy en un tableau zarr
compressor = Blosc(cname='zstd', clevel=3, shuffle=Blosc.BITSHUFFLE)
# Convertir l'image en tableau zarr
chunk_size = (100, 100)
zarray = zarr.array(image, chunks=chunk_size, compressor=compressor)
# sauvegarder zarr sur le disque
zarr_filename = '../../data/P1_H_C3H_M004_17-cropped.zarr'
zarr.convenience.save(zarr_filename, zarray)
Chargement de l’image sauvegardée en zarr#
Dask offre un support intégré pour le format de fichier zarr. Nous pouvons créer des tableaux dask directement à partir d’un fichier zarr.
zarr_image = da.from_zarr(zarr_filename)
zarr_image
|
Nous pouvons appliquer directement le traitement d’image à cet ensemble de données en tuiles.
Comptage des noyaux#
Pour compter les noyaux, nous mettons en place un simple flux de traitement d’image qui applique l’étiquetage Voronoi-Otsu à l’ensemble de données. Ensuite, nous comptons les objets segmentés. Comme les noyaux qui touchent le bord de la tuile pourraient être comptés deux fois, nous devons corriger le comptage pour chaque tuile. Techniquement, nous pourrions supprimer les objets qui touchent l’un des bords verticaux ou horizontaux de la tuile. Cependant, il existe une façon plus simple de corriger cette erreur : Nous comptons le nombre de noyaux après la segmentation. Ensuite, nous supprimons tous les noyaux qui touchent n’importe quel bord de l’image et comptons à nouveau les noyaux restants. Nous pouvons alors supposer que la moitié des noyaux supprimés devrait être comptée. Par conséquent, nous additionnons les deux comptages, avant et après la suppression des bords, et calculons la moyenne de ces deux mesures. En particulier sur de grandes tuiles avec de nombreux noyaux, l’erreur restante devrait être négligeable. Il n’est pas recommandé d’appliquer une telle méthode d’estimation du comptage cellulaire lorsque chaque tuile ne contient que peu de noyaux.
def count_nuclei(image):
"""
Étiqueter les objets dans une image binaire et produire une image de carte de comptage de pixels.
"""
print("Traitement de l'image de taille", image.shape)
# Compter les noyaux y compris ceux qui touchent le bord de l'image
labels = cle.voronoi_otsu_labeling(image, spot_sigma=3.5)
label_intensity_map = cle.mean_intensity_map(image, labels)
high_intensity_labels = cle.exclude_labels_with_map_values_within_range(label_intensity_map, labels, maximum_value_range=20)
nuclei_count = high_intensity_labels.max()
# Compter les noyaux y compris ceux qui touchent le bord de l'image
labels_without_borders = cle.exclude_labels_on_edges(high_intensity_labels)
nuclei_count_excluding_borders = labels_without_borders.max()
# Les deux comptages de noyaux, incluant et excluant les noyaux aux bords de l'image,
# ne sont pas de bonnes approximations. Nous devrions exclure les noyaux seulement sur
# la moitié des bords pour obtenir une bonne estimation.
# Alternativement, nous prenons simplement la moyenne des deux comptages.
result = np.asarray([[(nuclei_count + nuclei_count_excluding_borders) / 2]])
print(result.shape)
return result
Avant de pouvoir commencer le calcul, nous devons désactiver l’exécution asynchrone des opérations dans pyclesperanto. Voir aussi le problème lié.
cle.set_wait_for_kernel_finish(True)
Cette fois, nous n’utilisons pas de chevauchement de tuiles, car nous ne mesurons pas les propriétés des noyaux et n’avons donc pas besoin d’une segmentation parfaite de ceux-ci.
tile_map = da.map_blocks(count_nuclei, zarr_image)
tile_map
Processing image of size (0, 0)
Processing image of size (1, 1)
(1, 1)
Processing image of size (0, 0)
|
Comme l’image résultante est beaucoup plus petite que l’originale, nous pouvons calculer la carte de résultat complète.
result = tile_map.compute()
Processing image of size (100, 100)
Processing image of sizeProcessing image of size (100, 100)
Processing image of size (100, 100)
(100, 100)
Processing image of size (100, 100)
Processing image of size (100, 100)
Processing image of sizeProcessing image of size (100, 100)
Processing image of size(100, 100)
(100, 100)
Processing image of size (100, 100)
(1, 1)
(1, 1)
Processing image of size (100, 100)
(1, 1)
Processing image of size (100, 100)
Processing image of size (100, 100)
(1, 1)(1, 1)
Processing image of size (100, 100)
Processing image of size(1, 1)
(100, 100)
Processing image of size (100, 100)
(1, 1)
(1, 1)
Processing image of size (100, 100)
Processing image of size (100, 100)
(1, 1)
Processing image of size (100, 100)
(1, 1)
Processing image of size (100, 100)
(1, 1)
Processing image of size (100, 100)
(1, 1)
(1, 1)
Processing image of sizeProcessing image of size (100, 100)
(100, 100)
(1, 1)(1, 1)
(1, 1)
Processing image of size Processing image of size(100, 100) (1, 1)
(100, 100)
(1, 1)
(1, 1)
(1, 1)
(1, 1)
(1, 1)
(1, 1)
(1, 1)
(1, 1)
result.shape
(5, 5)
Encore une fois, comme la carte de résultat est petite, nous pouvons simplement la visualiser.
cle.imshow(result, colorbar=True)
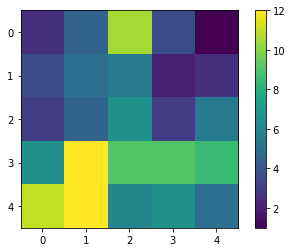
Avec une vérification visuelle rapide dans l’image originale, nous pouvons voir qu’effectivement dans le coin inférieur gauche de l’image, il y a plus de cellules que dans le coin supérieur droit.
cle.imshow(cle.voronoi_otsu_labeling(image, spot_sigma=3.5), labels=True)