(machine_learning_basics.scaling=)
Mise à l’échelle#
Lors de l’utilisation d’algorithmes d’apprentissage automatique pour le traitement des données, la plage des paramètres est cruciale. Pour obtenir différents paramètres dans la même plage, une mise à l’échelle peut être nécessaire.
Voir aussi
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# local import; this library is located in the same folder as the notebook
from data_generator import generate_biomodal_2d_data
data1 = generate_biomodal_2d_data()
plt.scatter(data1[:, 0], data1[:, 1], c='grey')
<matplotlib.collections.PathCollection at 0x7f79e40aeca0>
data2 = generate_biomodal_2d_data()
data2[:, 1] = data2[:, 1] * 0.1
plt.scatter(data2[:, 0], data2[:, 1], c='grey')
<matplotlib.collections.PathCollection at 0x7f7980026b80>
Clustering de données dans différentes plages#
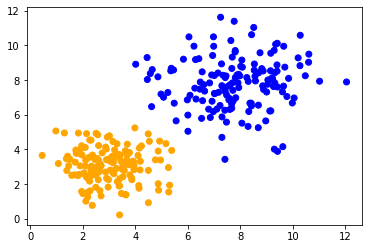
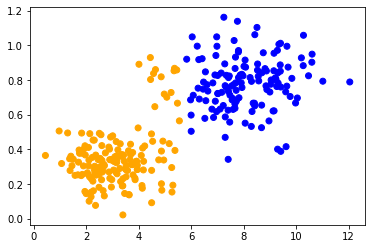
Nous allons maintenant regrouper les deux ensembles de données apparemment similaires en utilisant le clustering k-means. L’effet peut également être observé lors de l’utilisation d’autres algorithmes. Pour nous assurer que nous appliquons le même algorithme avec la même configuration aux deux ensembles de données, nous l’encapsulons dans une fonction et la réutilisons.
def classify_and_plot(data):
number_of_classes = 2
classifier = KMeans(n_clusters=number_of_classes)
classifier.fit(data)
prediction = classifier.predict(data)
colors = ['orange', 'blue']
predicted_colors = [colors[i] for i in prediction]
plt.scatter(data[:, 0], data[:, 1], c=predicted_colors)
En appliquant la même méthode aux deux ensembles de données, nous pouvons observer que les points de données au centre sont classés différemment. La seule différence entre les ensembles de données est leur plage de données. Les points de données sont mis à l’échelle différemment le long d’un axe.
classify_and_plot(data1)
classify_and_plot(data2)
Mise à l’échelle standard#
La mise à l’échelle standard est une technique pour changer la plage de données à une plage fixe, par exemple [0, 1]. Elle permet d’obtenir des résultats identiques dans le cas de données qui étaient dans des plages différentes.
def scale(data):
scaler = StandardScaler().fit(data)
return scaler.transform(data)
scaled_data1 = scale(data1)
classify_and_plot(scaled_data1)
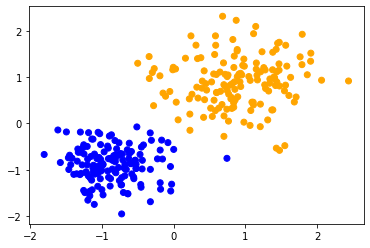
scaled_data2 = scale(data2)
classify_and_plot(scaled_data2)