Analyse quantitative d’image#
Après avoir segmenté et étiqueté les objets dans une image, nous pouvons mesurer les propriétés de ces objets.
Voir aussi
Avant de pouvoir faire des mesures, nous avons besoin d’une image et d’une image_étiquetée correspondante. Par conséquent, nous récapitulons le filtrage, le seuillage et l’étiquetage :
from skimage.io import imread
from skimage import filters
from skimage import measure
from pyclesperanto_prototype import imshow
import pandas as pd
import numpy as np
# load image
image = imread("../../data/blobs.tif")
# denoising
blurred_image = filters.gaussian(image, sigma=1)
# binarization
threshold = filters.threshold_otsu(blurred_image)
thresholded_image = blurred_image >= threshold
# labeling
label_image = measure.label(thresholded_image)
# visualization
imshow(label_image, labels=True)
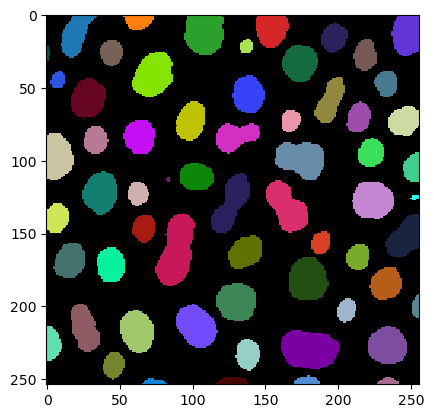
Mesures / propriétés des régions#
Pour lire les propriétés des régions, nous utilisons la fonction regionprops :
# analyse objects
properties = measure.regionprops(label_image, intensity_image=image)
Les résultats sont stockés sous forme d’objets RegionProps, qui ne sont pas très informatifs :
properties[0:5]
[<skimage.measure._regionprops.RegionProperties at 0x1c272b8f8e0>,
<skimage.measure._regionprops.RegionProperties at 0x1c26d278af0>,
<skimage.measure._regionprops.RegionProperties at 0x1c26d2784c0>,
<skimage.measure._regionprops.RegionProperties at 0x1c26d278b20>,
<skimage.measure._regionprops.RegionProperties at 0x1c26d278b80>]
Si vous voulez savoir quelles propriétés nous avons mesurées : Elles sont listées dans la documentation de la fonction measure.regionprops. En gros, nous avons maintenant une variable properties qui contient 40 caractéristiques différentes. Mais nous ne sommes intéressés que par un petit sous-ensemble d’entre elles.
Par conséquent, nous pouvons réorganiser les mesures dans un dictionnaire contenant des tableaux avec nos caractéristiques d’intérêt :
statistics = {
'area': [p.area for p in properties],
'mean': [p.mean_intensity for p in properties],
'major_axis': [p.major_axis_length for p in properties],
'minor_axis': [p.minor_axis_length for p in properties]
}
La lecture de ces dictionnaires de tableaux n’est pas très pratique. Pour cela, nous introduisons les DataFrames pandas qui sont couramment utilisés par les data scientists. “DataFrames” est juste un autre terme pour “tableaux” utilisé en Python.
df = pd.DataFrame(statistics)
df
| area | mean | major_axis | minor_axis | |
|---|---|---|---|---|
| 0 | 429 | 191.440559 | 34.779230 | 16.654732 |
| 1 | 183 | 179.846995 | 20.950530 | 11.755645 |
| 2 | 658 | 205.604863 | 30.198484 | 28.282790 |
| 3 | 433 | 217.515012 | 24.508791 | 23.079220 |
| 4 | 472 | 213.033898 | 31.084766 | 19.681190 |
| ... | ... | ... | ... | ... |
| 57 | 213 | 184.525822 | 18.753879 | 14.468993 |
| 58 | 79 | 184.810127 | 18.287489 | 5.762488 |
| 59 | 88 | 182.727273 | 21.673692 | 5.389867 |
| 60 | 52 | 189.538462 | 14.335104 | 5.047883 |
| 61 | 48 | 173.833333 | 16.925660 | 3.831678 |
62 rows × 4 columns
Vous pouvez également ajouter des colonnes personnalisées en calculant votre propre métrique, par exemple le rapport d'aspect :
df['aspect_ratio'] = [p.major_axis_length / p.minor_axis_length for p in properties]
df
| area | mean | major_axis | minor_axis | aspect_ratio | |
|---|---|---|---|---|---|
| 0 | 429 | 191.440559 | 34.779230 | 16.654732 | 2.088249 |
| 1 | 183 | 179.846995 | 20.950530 | 11.755645 | 1.782168 |
| 2 | 658 | 205.604863 | 30.198484 | 28.282790 | 1.067734 |
| 3 | 433 | 217.515012 | 24.508791 | 23.079220 | 1.061942 |
| 4 | 472 | 213.033898 | 31.084766 | 19.681190 | 1.579415 |
| ... | ... | ... | ... | ... | ... |
| 57 | 213 | 184.525822 | 18.753879 | 14.468993 | 1.296143 |
| 58 | 79 | 184.810127 | 18.287489 | 5.762488 | 3.173540 |
| 59 | 88 | 182.727273 | 21.673692 | 5.389867 | 4.021193 |
| 60 | 52 | 189.538462 | 14.335104 | 5.047883 | 2.839825 |
| 61 | 48 | 173.833333 | 16.925660 | 3.831678 | 4.417297 |
62 rows × 5 columns
Ces dataframes peuvent être sauvegardés sur le disque de manière pratique :
df.to_csv("blobs_analysis.csv")
De plus, on peut mesurer les propriétés de notre tableau statistics en utilisant numpy. Par exemple, l’aire moyenne :
# measure mean area
np.mean(df['area'])
355.3709677419355
Exercices#
Analysez l’image de blobs chargée.
Combien d’objets y a-t-il dedans ?
Quelle est la taille du plus grand objet ?
Quelles sont la moyenne et l’écart-type de l’image ?
Quelles sont la moyenne et l’écart-type de l’aire des objets segmentés ?