Apprentissage automatique non supervisé#
L’apprentissage automatique non supervisé est une technique pour configurer (apprendre) les paramètres d’un modèle computationnel basé sur aucune annotation mais avec des informations supplémentaires telles que le nombre de catégories à différencier. De nombreux algorithmes dans cette catégorie effectuent un clustering des données.
Voir aussi
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.cluster import KMeans
# local import; this library is located in the same folder as the notebook
from data_generator import generate_biomodal_2d_data
Notre point de départ pour démontrer l’apprentissage automatique supervisé est une paire de mesures dans une distribution bimodale. Dans l’ensemble de données suivant, les objets avec une plus grande surface sont typiquement aussi plus allongés.
data = generate_biomodal_2d_data()
plt.scatter(data[:, 0], data[:, 1], c='grey')
<matplotlib.collections.PathCollection at 0x7fd53c2d7c70>
Dans le cas des algorithmes d’apprentissage automatique non supervisé, nous devons fournir des informations supplémentaires à l’algorithme afin qu’il puisse séparer (clustériser) les points de données en régions de manière significative. Les informations que nous fournissons dépendent de l’algorithme et de la distribution des données. Typiquement, nous sélectionnons l’algorithme en fonction des données. Dans l’exemple ci-dessus, nous pouvons clairement voir deux clusters, c’est une distribution bimodale. Dans ce cas, nous pouvons spécifier le nombre de classes à différencier :
number_of_classes = 2
Initialisation du clustering k-means#
Le clustering k-means est un algorithme qui regroupe les points de données en k clusters de sorte que tous les points de données soient assignés au centre le plus proche des clusters.
Les algorithmes de clustering dans scikit-learn ont généralement une fonction fit() qui consomme un ensemble de data comme donné ci-dessus.
classifier = KMeans(n_clusters=number_of_classes)
classifier.fit(data)
KMeans(n_clusters=2)
Prédiction#
Après que le modèle soit entraîné (ou ajusté), nous pouvons l’appliquer à nos données pour obtenir une prédiction sur le cluster auquel appartiennent les points de données. L’indexation des clusters commence à 0. Ainsi, si nous avons demandé de différencier deux clusters, les indices des clusters sont 0 et 1 :
prediction = classifier.predict(data)
prediction
array([0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0,
0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0,
1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 1,
1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0,
1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1,
0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1,
1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0,
0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1,
0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0,
0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1,
0, 0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0,
0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 1, 0, 1,
1, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1], dtype=int32)
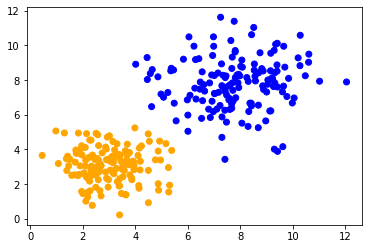
Nous pouvons ensuite visualiser toutes les classes prédites en couleurs.
colors = ['orange', 'blue']
predicted_colors = [colors[i] for i in prediction]
plt.scatter(data[:, 0], data[:, 1], c=predicted_colors)
<matplotlib.collections.PathCollection at 0x7fd4d8018d30>
Exercice#
Entraînez un Modèle de Mélange Gaussien et visualisez sa prédiction.
from sklearn.mixture import GaussianMixture
classifier = GaussianMixture(n_components=2)