Fusion d’objets à l’aide de l’apprentissage automatique
L’ObjectMerger est un Classificateur de Forêt Aléatoire faisant partie de la bibliothèque apoc qui peut apprendre quelles étiquettes fusionner et lesquelles ne pas fusionner. Il permet le post-traitement des images d’étiquettes après que les objets ont été (intentionnellement ou non) sur-segmentés.
Un exemple courant peut être dérivé d’une image montrant des intensités dans les membranes cellulaires.

|
cle._ image
| shape | (256, 256) |
| dtype | float32 |
| size | 256.0 kB |
| min | 277.0 | | max | 44092.0 |

|
Comme les membranes ont des intensités différentes selon la région de l’image, nous devons d’abord corriger cela.

|
cle._ image
| shape | (256, 256) |
| dtype | float32 |
| size | 256.0 kB |
| min | 0.15839748 | | max | 11.448771 |

|
Pour des raisons techniques, il est également recommandé de transformer l’image d’intensité en une image de type entier. Par conséquent, une normalisation peut être nécessaire. Il est important que les images utilisées pour l’entraînement et les images utilisées pour la prédiction aient des intensités dans la même plage.

|
cle._ image
| shape | (256, 256) |
| dtype | uint32 |
| size | 256.0 kB |
| min | 1.0 | | max | 54.0 |
|
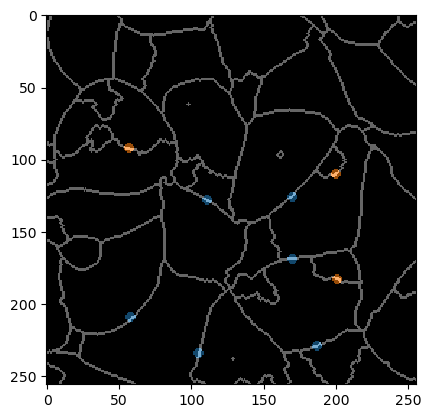
Une annotation sert à indiquer à l’algorithme quels objets segmentés doivent être fusionnés et lesquels ne doivent pas l’être.

|
cle._ image
| shape | (256, 256) |
| dtype | uint32 |
| size | 256.0 kB |
| min | 0.0 | | max | 2.0 |
|
À des fins de visualisation, nous pouvons superposer l’annotation avec l’image de la membrane.
Pour montrer plus précisément ce qui doit être annoté, nous superposons également l’image des bords d’étiquettes et l’annotation. Notez que les bords qui ne sont pas censés être fusionnés sont de petits points annotant toujours soigneusement seulement deux objets (qui ne doivent pas être fusionnés).
Entraînement du fusionneur
Le LabelMerger peut être entraîné en utilisant trois caractéristiques :
touch_portion : La quantité relative de contact d’un objet avec un autre. Par exemple, dans un tissu symétrique en nid d’abeille, les cellules voisines ont une portion de contact de 1/6 entre elles.
touch_count : Le nombre de pixels où les objets se touchent. Lors de l’utilisation de ce paramètre, assurez-vous que les images utilisées pour l’entraînement et la prédiction ont la même taille de voxel.
mean_touch_intensity : L’intensité moyenne entre les objets qui se touchent. Si une cellule est sur-segmentée, plusieurs objets sont trouvés à l’intérieur de cette cellule. La zone où ces objets se touchent a une intensité plus faible que la zone où deux cellules se touchent. Ainsi, ils peuvent être différenciés. La normalisation de l’image comme montré ci-dessus est essentielle.
centroid_distance : La distance (en pixels ou voxels) entre les centroïdes des objets étiquetés.
Note : il est recommandé d’utiliser la plupart des caractéristiques uniquement dans des images isotropes.

|
cle._ image
| shape | (256, 256) |
| dtype | uint32 |
| size | 256.0 kB |
| min | 1.0 | | max | 31.0 |
|